このサイトのコンテンツは個人の意見で会社を代表しません
Cache Details
概要
This post represents my first attempt to implement the simplest possible texture cache that still works with my current GPU, in preparation for getting texturing working. Originally, it wasn’t meant to be a releasable post, but rather was written before coding the cache as a way to work out the high level design ideas and to find potential issues. Turns out pretending to explain my ideas to a fictional reader works really well for me as a way of designing. As a bonus, it’s also a way to help me remember how my own stuff works, should work get busy and I need to come back to the project after N months. The cache is currently working both in sim and in hardware, but with fake values stuffed into memory instead of actual textures
Cache Organisation
The texture cache is a read-only cache with LRU policy and single-clock invalidation. The cacheline size is 256 bits, which is 16 pixels in 565 format, representing a 4×4 tiled block. The data store for the cache is built out of pairs of 36 kbit simple dual-port BRAMs. This appears to be a requirement stemming from the cache having asymmetric read and write sizes (one pixel reads and half cacheline writes). This gives a total memory size of 72 kbits, or 256 lines, if ECC isn’t repurposed as usable data. And with a 2-way cache, that is 128 sets. Therefore read addresses presented to the cache will have 4 bits indicating the pixel within a line, 7 bits to determine the set, and the MSB 16 bits will be the tag
The tags are kept separate from the cache datastore. Each line has a 16 bit tag, and a valid bit, and each set has shares one bit to indicate which way is LRU. This data doesn’t represent the actual current state of the cache, but rather the state the cache will be in once the next request is processed.
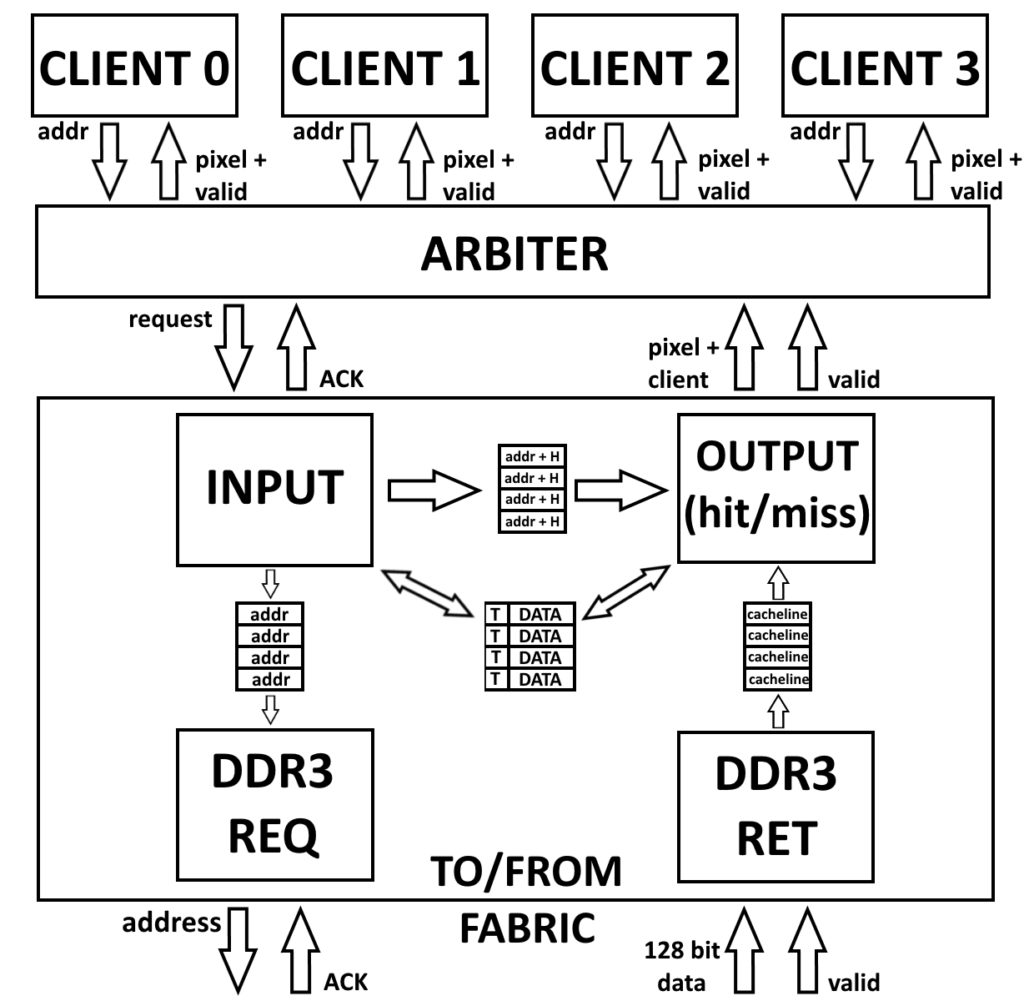
Client Arbiter
Each cache serves four clients. To give me the simplest test, the clients are currently just the rasterizer tiles, although eventually I may try to add texture reads to my pixel shaders. Each client can have multiple requests in flight, and data is returned in the order that requests are accepted.
The arbiter chooses a client request with a simple four bit rotating onehot mask, where the set bit determines the first client to consider. So if the mask was 4’b0100, the arbiter would start with client 2, and then try 3, 0, and 1 in order, looking for a valid request. A mask of 4’b0010 would check clients 1, 2, 3, and then 0. The priority mask is rotated one bit left when a request is accepted. Early on I tried to be more “clever” with arbitration, favouring client requests that would be hits before ones that would be misses, but this really complicated the design and made it harder to meet timing. It also starved the cache of DDR3 requests that could have been in flight.
The arbiter itself is a two state machine. In the first state, it looks for a valid client request. If one is found, it saves off the request address and client number, presents the request to the cache, rotates the accept mask, and notifies the client that it’s request was accepted, before transitioning to the second state. The second state simply waits for the ack from the cache, which usually comes within two clocks unless the cache input FIFO is full or it’s not in the request accept state.
Requests consist of only an address and client ID. Because we have 256MB of RAM, the full address width is 28 bits. However, cache requests are for 16 bit pixels, meaning the LSB of the address isn’t needed in the request, and so request addresses are 27 bits wide. Client ID is just a 2 bit number indicating client. This ID is returned by the cache, along with the pixel data, and is used to signal a client that there is valid data for them on the bus.
Cache Input Processing
The cache itself is made of four state machines: input, DDR request, DDR return, and output. The input machine is a three state FSM where the first state accepts and saves off an incoming request from the arbiter, the second state gets the tags and LRU bit for the relevant cache set, and the third state updates the cache tags, adds misses to the DDR3 request FIFO, and adds the request to the output request FIFO.
The output request FIFO entry contains a client number, one bit to indicate whether a request is a hit or miss, and some address information. Cache reads are pixel aligned, and so the read address is constructed as {set_bits (7b), way (1b), pixel bits (4b)}. Writes are half cacheline granularity, and so the addresses are {set_bits (7b), way (1b), halfline (1b)}, but the halfline isn’t needed until a miss’s data is returned from the memory fabric, and therefore isn’t stored in the output request FIFO entry.
The cache tags and LRU bits are stored separately from the cacheline data, and don’t reflect the current state of the cache. For example, a miss will set the valid bit so that the next request for the address will be a hit, even though the data is not yet in the cache. The cache is updated with the following pseudocode:
cache_set_flags[input_req_addr.set].lru <= |input_is_hit ? input_is_hit[0] : ~input_set_flags.lru;
cache_set_flags[input_req_addr.set].tag_entry[input_way_to_use] <= {1'b1, input_req_addr.tag};
input_is_hit is a two bit vector (one for each way), that is guaranteed to be either zero in the case of a miss, or $onehot for a hit. The bitwise-or reduction of this, |input_is_hit, indicates whether the request hit in any way. In the case of a hit, the set’s LRU bit is set to input_is_hit[0], so that LRU is now set to whatever way we didn’t hit in. Otherwise for a miss, the current LRU bit is just inverted. The tag_entry is always updated, either with the existing tag for a hit, or the new tag for a miss.
DDR3 Request Processing
In the case of a miss, the input FSM adds memory requests to a CDC FIFO for the DDR3 request FSM to consume, with the write side clocked at the system clock frequency, and the read side clocked at the much lower DDR3 controller user interface frequency. The DDR3 request addresses are just the upper 23 bits of the byte address. This is because byte addresses are 28 bit and cache request addresses are 27 bits (since pixels are 2 bytes), but I want DDR3 request addresses to be cache line aligned. With a cache line holding 16 pixels, this means DDR3 request addresses only need 28 – $clog2(2) – $clog2(32/2) = 23 bits. It is this 23 bit address and the number of 128 bit reads (two for a 256 bit cacheline) that is sent over the fabric.
The DDR3 request FSM is a simple two state machine. The first gets an entry from the DDR3 request FIFO, if there are any. The second state presents the request to the memory fabric, and waits for the ack to come beck before getting the next FIFO entry.
DDR3 Return Processing
Data returned from the memory fabric is 128 bits wide, but cachelines are 256 bits, so I have some logic to gather the returned data into cachelines before adding to the return data FIFO. This is actually really simple, and just requires a single bit to indicate whether incoming data is the high 128 or low 128, and a 128 bit vector to store the previously returned data. And so the return data FIFO input becomes {new_data_from_ddr, prev_data_from_ddr}, and the FIFO write enable is (valid_data & is_high_128).
Output Block
Here’s where I admit I have been lying. The output FSM is actually two FSMs: one for hit processing and another for misses.
Hit FSM
The hit machine has four states. The first state waits for a valid entry in the output request FIFO. Once output_fifo_empty goes low, the request is saved off, the cache address is sent to the BRAM, and it transitions to the second state. All the second state does is transition to the third state, to give the BRAM time to return the requested data. In the third state, the output pixel is read from the BRAM, and it transitions to the final sync state.
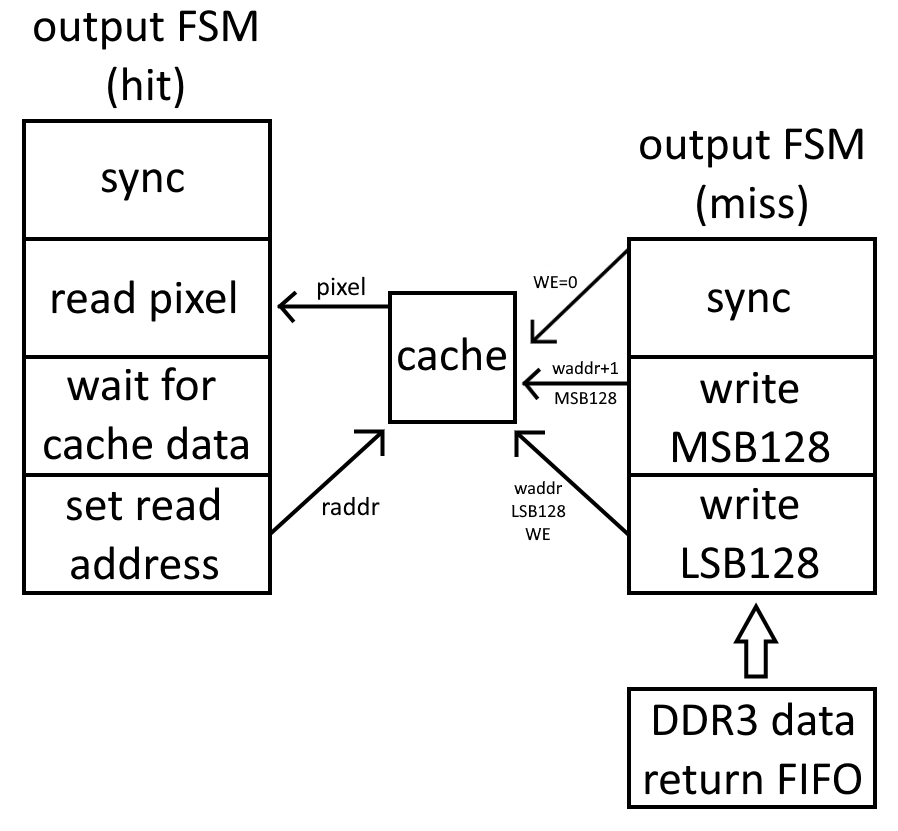
Miss FSM
The write machine only has three states. Like the read machine, the write machine initial state also waits until output_fifo_empty goes low, but it also waits for (was_hit | ~ddr3_ret_fifo_empty). This is because in the case of a hit, the write machine has nothing to do and can safely continue. But in the case of a miss, it also has to wait until the required data is returned from the memory fabric. Once the condition is met, the cacheline data is read from the DDR3 return FIFO. The lower 128 bits of that data, the cache write address, and the write enable bit (high if the request was a miss) are sent to the BRAM, and it transitions to the second state. In the second state, the BRAM address is incremented and the upper 128 bits of the cacheline are sent to the BRAM. Like the read machine, the final state is the sync state, which waits for both FSMs to enter into sync, before transitioning back to the first state.
SVA Verification
The bulk of architectural asserts in the cache are for verifying FIFOs, checking for overflow, underflow, and validity, and making sure that the FIFO element sizes match what was set up in the IP. The rest are sanity checks verifying the expected flow of the various FSMs. For example, if an output request FIFO entry is a miss, once the data from memory is available, the cache write enable should rise, stay asserted for two clocks, and then fall. There are also quite a few internal consistency asserts, such as making sure a request never hits in more than one way, that valid bits go low one clock after an invalidation, DDR return FIFO must be empty if the output request FIFO is empty, and that data from the cache is valid exactly two clocks after a read request.
There are some asserts in the arbiter as well. Most of these are sanity checks like the accepted client must actually have a valid request, the client request bit goes low one clock after the arbiter accepts a request, and that the arbiter FSM must be in the kArbStateWaitCacheAck state when the cache asserts arb2cache_if.req_accepted. I bring these three up as an example because all three of the were failing due to a stupid typo that I feel really should have been an error, or at least a warning. Thanks, Vivado. The lesson here is to assert everything, no matter how stupid or small it may seem.
Finally, testbench asserts are used to verify correct high level operation. Each test has three modes: linear, all misses, and alternating ways. Linear uses linearly increasing addresses, and verifies both that the data returned is correct and that I get 1 miss followed by 15 hits. The all misses mode requests the first pixel of every cacheline, and so asserts check that every request is a miss. Alternating ways is a bit harder to explain. Basically I want to test
- [tag A, set 0, way 0: miss]
- [tag B, set 0, way 1: miss]
- [tag A, set 0, way 0: hit]
- [tag B, set 0, way 1: hit]
- [tag C, set 2, way 0: miss]
- [tag D, set 2, way 1: miss]
- [tag C, set 2, way 0: hit]
- [tag D, set 2, way 1: hit]
- [tag E, set 1, way 0: miss]
- [tag F, set 1, way 1: miss]
- [tag E, set 1, way 0: hit]
- [tag F, set 1, way 1: hit]
Future Optimisations
Like I said, this represents a first attempt at getting something simple up and running, and in doing so I took quite a few shortcuts. Currently, data is returned in the order requests are accepted, and a miss can block subsequent hits. I’m considering having per-client queues in the cache, where requests from a particular client are always processed in order, but there is some freedom to return a hit from client A while client B’s miss is pending. I actually looked into this pretty early on, but it really complicated the design. I may have to come back to this in the future if I am feeling brave
Fake Scanout Demo
So, why fake a demo? Well, lighting up a green LED on test success is fine, but this is a “GPU” so it would be nice to see something visual on screen. The current rasterizer is a remnant from my previous tile racing design, and rewriting it to support texturing and framebuffers is going to take a Very Long Time. So in order to get some visual confirmation that the texture caches and memory fabric are working, I tried to come up with a minimal work demo that would get some textures displaying.
Demo Setup
I tried to keep the demo as close as possible to the final GPU configuration. So there are twenty “rasterizers”, each covering a 32×32 pixel tile, or a total area of 640×32. Four rasterizers share a texture cache, and so there are five texture caches. These five caches talk to DDR3 through a memory fabric arbiter, which is also shared with a single write client that fills RAM with tiled texture data stored in a BRAM. The addressing used is identical to the final addressing calculation, except that the texture width is locked to 256 pixels. The fake rasterizers themselves don’t do any rasterization. Rather they only contain two state machines: one for requesting the needed texels and the other for receiving them from the cache.
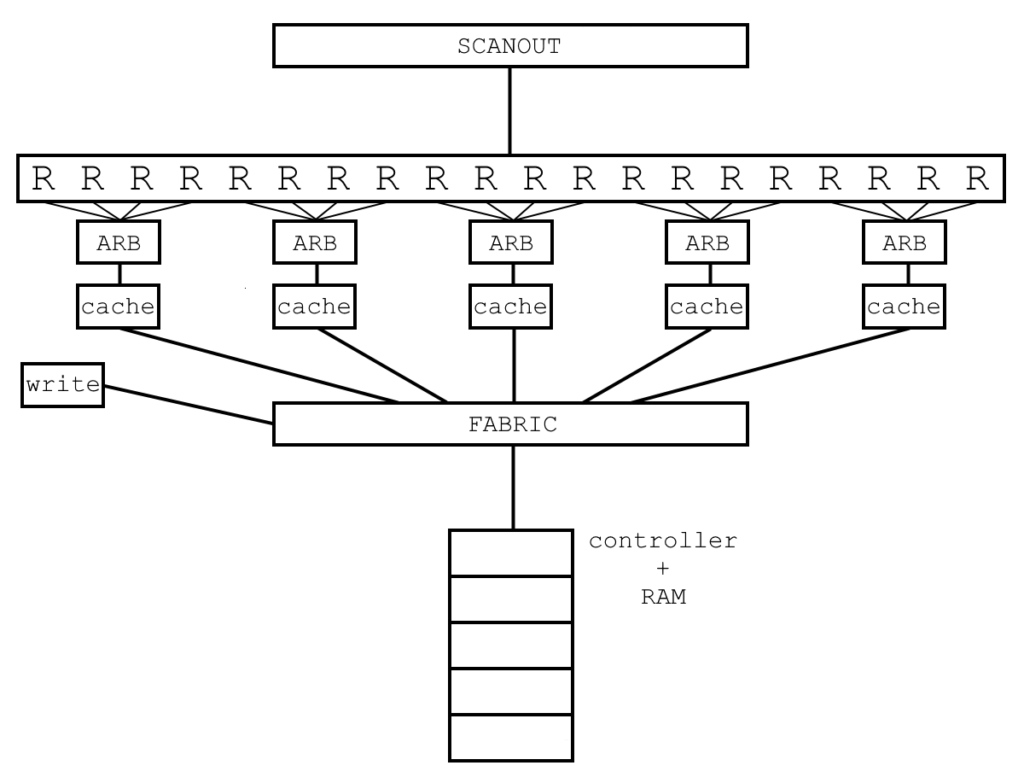
DDR3 Fabric and Arbiter
To save time, the memory fabric arbiter is based on the cache client arbiter, but with some modifications. The biggest of these is that there are now both read and write clients, the number of clients is increased from four to six, and the priority is now fixed based on client number. In the demo, client 0 is the write client. It fills RAM with texture data and then goes idle forever, and so it’s given the highest priority to allow it to finish before any reads occur. For read clients, client 1 has the highest priority and client 5 has the lowest, since client 1 handles pixels on the left side of the screen which are needed before client 5’s right side of the screen pixels.
The other major modification is that data coming back from memory can can consist of a variable number of 128 bit transactions, rather than always being one like for the cache arbiter, and so the transaction count (minus one) needs to be sent to the DDR3 state machine. For writes, I’m only writing 128 bits at a time, so the number of transactions is always one. For reads, this is currently always going to be two since the only read client is the caches, and caches want to fill 128×2=256 bit cachelines.
When a read request comes along, the requesting client number is put in a FIFO. When data comes back from memory, a return transaction counter is incremented, and when the counter has all bits set, the client number FIFO has its read signal asserted to move on to the next entry. This allows me to add the client number to the FIFO once, even though I’m expecting two transactions back.
DDR3 State Machine
The memory controller has two separate and (semi) independent paths: a command path that takes a command (read or write) and address, and a write data path for storing data to write. The write data can be added before the command, on the same clock as the command, or up to two clocks after the command is added. But because the command path can become unavailable (app_rdy goes low) for long periods of time, it was safer to always add the write data first, if its a write command. And so the state for adding write data looks like
app_en <= 0; calibration_success <= 1; read_transaction_count <= from_ddr3_arb_if.read_transaction_count; app_addr <= (from_ddr3_arb_if.req_addr << kDdr3ReqAddrToFullAddrShift); app_cmd <= from_ddr3_arb_if.req_is_read; // if a valid read comes in, or a write comes in and there is space in the write data FIFO if (from_ddr3_arb_if.req_valid & (from_ddr3_arb_if.req_is_read | app_wdf_rdy)) begin app_wdf_wren <= ~from_ddr3_arb_if.req_is_read; from_ddr3_arb_if.req_accepted <= 1; app_en <= 1; current_state_ui <= kStateAddCommand; end
And the state for adding commands (one per transaction) just becomes the following simple loop
// but requests consist of multiple contiguous transactions, so count down read_transaction_count <= read_transaction_count - app_rdy; app_addr <= app_addr + (app_rdy << kTransactionIncShift); app_en <= ~app_rdy || |read_transaction_count; current_state_ui <= app_rdy && (read_transaction_count == 0) ? kStateWaitRequest : kStateAddCommand;
The return data logic simply waits for app_rd_data_valid to go high and then assigns from_ddr3_arb_if.ret_data <= app_rd_data and then from_ddr3_arb_if.ret_valid <= app_rd_data_valid;
Fake Rasterizers
These aren’t really rasterizers, as they don’t do any rasterizing, but rather are just stand-ins for the 20 rasterizer tiles I will eventually have to update to work with texturing. For now, think of them as just FSMs that request and receive texels from the texture caches.
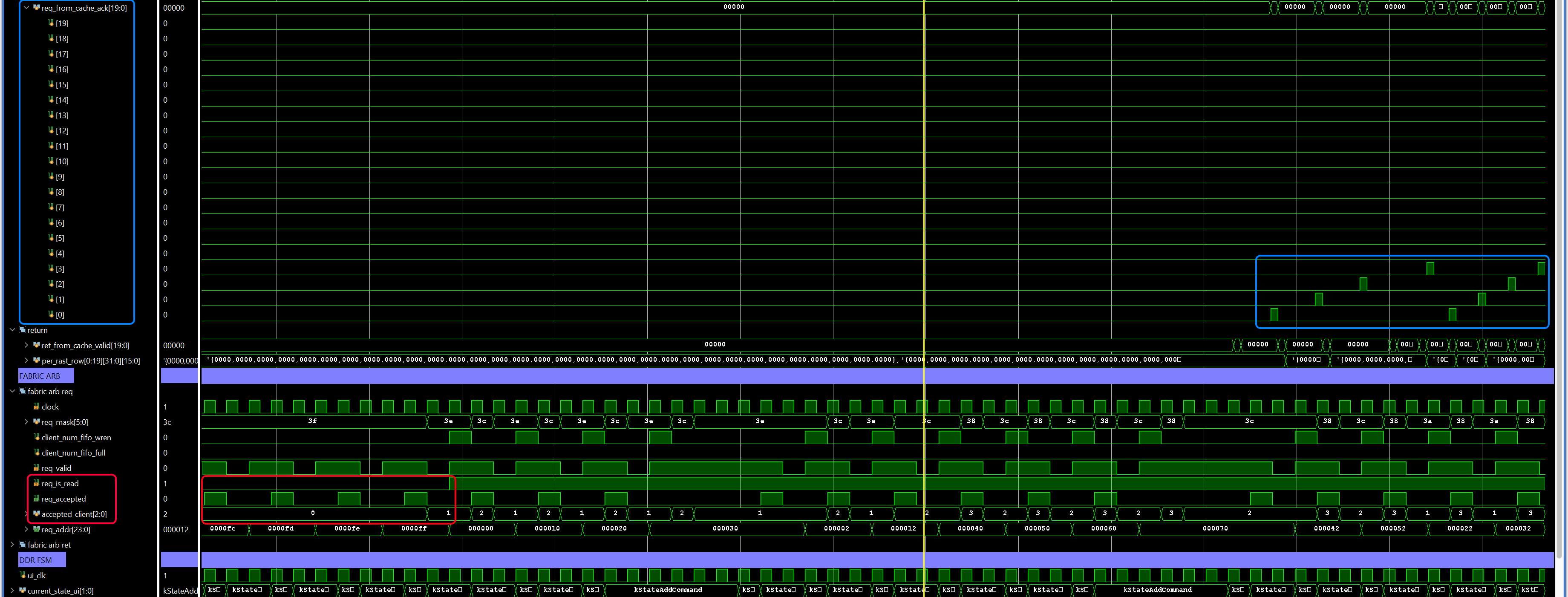
Cache Request
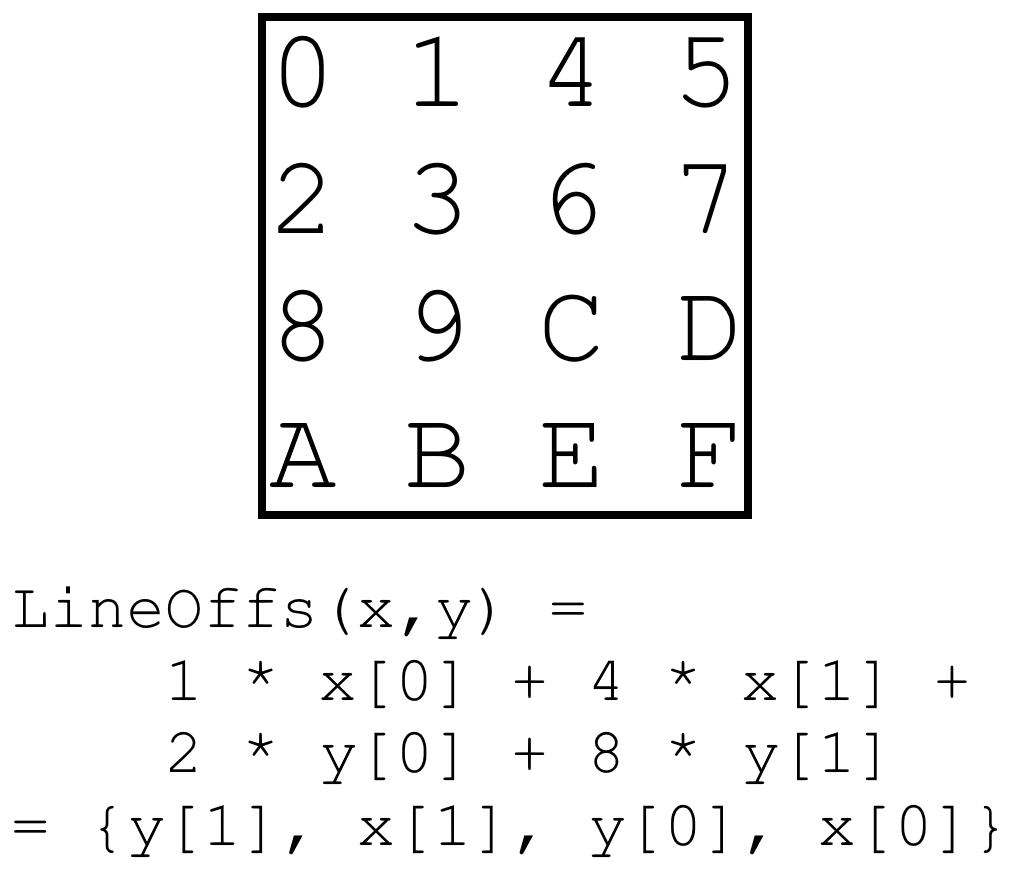
The request FSM begins when receiving a signal from HDMI, and requests 32 contiguous (in X) texels from the texture cache. Texture data is tiled as shown in figure 1, and therefore the texel address is computed as
// shouldn't really require any muls and adds. Everything is just a vector insert
function TexCacheAddr PixelXyToCacheAddr(input FakeTexCoord x_in, input FakeTexCoord y_in);
return (x_in >> 2) * 16 // start of 4x4 tile in a row
+ (y_in >> 2) * (kFakeTextureWidth * 4) // start of 4x4 tile in a col
+ {y_in[1], x_in[1], y_in[0], x_in[0]}; // offset inside the tile
endfunction
Once all 32 requests are accepted by the cache, the FSM transitions to idle and waits for HDMI to signal the next scanline’s data is needed.
Cache Return
The return FSM waits for data to come back from the cache, and builds up a per-rasterizer vector of the last 32 texels returned.
logic [kNumRastTiles-1:0] ret_from_cache_valid;
generate
// sadly Vivado won't let you index into interfaces with for loop variables
for (tg = 0; tg < kNumRastTiles; ++tg) begin
assign ret_from_cache_valid[tg] = cache_client_ifs[tg>>2][tg&3].ret_valid;
end
endgenerate
// per rasterizer cache read
always_ff @(posedge clock_in_200MHz_rasterizer) begin : PER_RAST_READ
for (int t = 0; t < kNumRastTiles; ++t) begin
if (ret_from_cache_valid[t]) begin
// {old_pix, new_pix} = (old_pix << 16) | new_pix
per_rast_row[t] <= (per_rast_row[t] << $bits(CachePixel)) | ret_data_from_cache[t >> $clog2(kNumClientsPerTextureCache)];
end
end
end : PER_RAST_READ
Here per_rast_row[t] is the per-rasterizer vector of 32 texels that is eventually passed to scanout to be used as the colour data. ret_from_cache_valid[t] is asserted if the cache is returning valid texels for client t, and ret_data_from_cache is the per-cache returned texel data.
HDMI Scanout
HDMI processing is largely unchanged from previous GPUs. There are three clock domains: a 25MHz pixel clock, a 250MHz TMDS clock, and a clock that runs at the GPU system clock. That final one is responsible for interfacing between scanout and the rest of the GPU.
The interface block is the most “interesting” bit. It signals the fake rasterizers to start requesting texels when
(pixelX == gHdmiWidth - 7) && (pixelY >= gHdmiHeight-2 || pixelY < gHdmiHeightVisible-2)
This because to request texels for line N, I want to get them from the cache during line N-1, which means kicking everything at the end of line N-2. Here, gHdmiHeight is 525 lines, and so I want to start when the line == 523 or when line < 480-2.
The interface block also signals the fake rasterizers to latch or shift out the fetched texels, shift register style. The latch happens when
(pixelX == gHdmiWidth - 7) && (pixelY == gHdmiHeight-1 || pixelY <= gHdmiHeightVisible-2)
Results

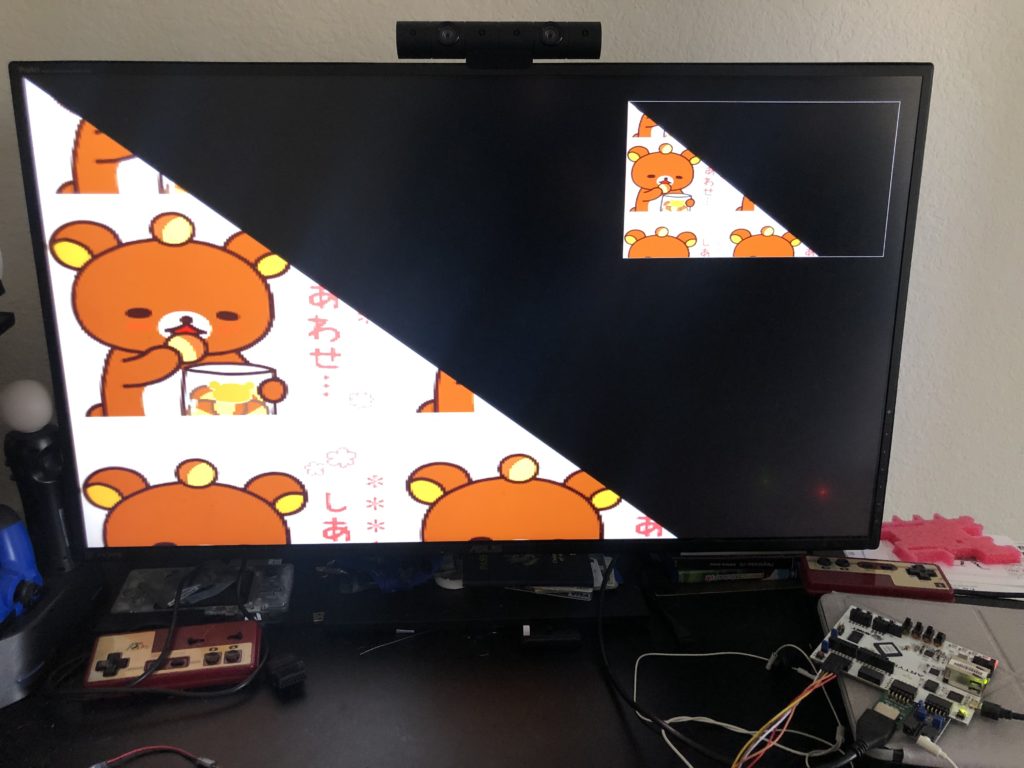
A fun historical note
This post was published on 2021/06/27. Last night I was banging my head against a wall (figuratively) trying to figure out the final RTL bug in the texturing demo. I woke up, having apparently dreamt the solution, ran to my computer and confirmed the fix. Finally being able to relax, I checked facebook where I was greeted with this amazingly timed memory from exactly one year ago today!

So yeah, see you on 2022/06/27 for a faked depth buffer demo, I guess?
Special Thanks
As always, thanks to @domipheus, @CarterBen, @Laxer3A, and @sparsevoxel for keeping me inspired with their absolutely mental projects.Thanks to @blackjero for instilling in me the importance of debugging graphics by actually putting things on screen instead of stuffing numbers into buffers.
And super mega ultra thanks to @mikeev, @tom_forsyth, @rygorous, and everyone else participating in the twitter FPGA threads. Its an honour being able to ask such accomplished professionals so many stupid questions and not get laughed out of the room