このサイトのコンテンツは個人の意見で会社を代表しません
Warning: this block entry is constantly being updated as I think of things to add. If you have questions or things you think should be covered, please leave them in the comments below.
概要
The Arty A7 comes with 256MB of DDR3L, but actually using it isn’t always the simplest thing. Unlike the Zync series, there is no hard IP for memory controllers, and so you have to roll your own or use Xilinx’s soft IP. There is no one definitive guide (that I could find), and there is quite a bit of wrong information out there. Much of the needed info either doesn’t exist, is spread out all over the internet, or assumes a good deal of previous FPGA experience to understand. So therefore, I am writing this blog post as a place to hold all my notes, because I will most certainly forget all of it in the near future.
Requirements for following along are: an Arty A7 board, Vivado (I am using 2021.1), Windows 10, infinite patience for dealing with Vivado’s bugs, and way too much free time to read a super long and dry blog post that explicitly spells out every step of the process.
Controller Levels
Vivado uses IP called MIG for generating DDR controllers. MIG stands for Massively Insufferable Garbage, and is basically a GUI where you specify the parameters of your memory, and it crashes… err, I mean creates a controller for you. There are four levels of controller this blog post mentions, but sadly the only two that MIG can create are AXI and UI. However, the UI controller can be used as a base for creating your own native controller.
AXI
The MIG IP gives you the option to generate an AXI interface. AXI is, to directly steal text from wikipedia, part of the ARM Advanced Microcontroller Bus Architecture 3 (AXI3) and 4 (AXI4) specifications, and is a parallel high-performance, synchronous, high-frequency, multi–master, multi-slave communication interface, mainly designed for on-chip communication. If that sounds like your jam, then AXI might be for you.
UI
UI is the other interface that MIG can generate. It’s a bit high level and allows you to add read and write commands fairly easily, while handling things like data reordering and user address mapping for you.
Native
UI is a convenience wrapper on top of the native layer. If you don’t need some of the UI helper functionality, such as reordering requests, you can get better latency by going with native directly. The MIG manual has some very sparse details on how native is supposed to work, but sadly MIG has no option to generate a native-level controller. The best option I’ve come up with so far is generating a UI controller, and then modifying the generated IP to make it do what you want
PHY
This is the real live boy. At the PHY level, you are worrying about temperature, refreshing cells, and directly driving memory signals. Not recommended for beginners, but I purposely chose a board with no DDR controller hard IP in the hopes that someday working out how to write a controller at this level. I am nowhere near that yet. Give me a few years.
DDR3 Refresher
This is meant to serve as a quick refresher of things that would be useful to know when generating and using the controller. It is in no way meant to be a exhaustive explanation of the inner workings of DDR3 or SDRAM
Structure
DDR3 consists of ranks, banks, rows, and columns. The A7 is a single rank configuration, and so the rank number will always be 0. Each rank consists of 8 banks, each bank is made up of 2^14=16,384 rows, and each row is made up of 2^10=1024 columns. Therefore the total number of columns would be 8 x 16,384 x 1024 = 134,217,728. If we have 256MB of memory, that’s 256MB / 134,217,728 = 2 bytes, or 16 bits per column which is what we’d expect.
Address Encoding
All this row and column business is important for performance reasons. To use a row, it must first be opened which can take some of time. Each bank can have one row open, but not multiple rows per bank. Once a row is opened, subsequent accesses to it’s columns are less expensive, but as a general rule you don’t want to be unnecessarily opening a new row every access. Vivado’s memory controller generator gives you two options for address encoding: {row, bank, column} and {bank, row, column}. In {row, bank, column}, you go through all 1024 columns and then increment the bank. Because there are 8 banks, this gives you one giant contiguous working area of 8 banks x 1024 columns x 2 bytes/column, or 16,384 bytes that can be randomly accessed without having to reopen a row.
Address encoding {bank, row, column} is useful in a different situation. Instead of each bank contributing a row to form one big contiguous area, here each bank has its own 32MB area, of which only one 2048 byte row can be open at a time. This can be useful in situations where you have different memory fabric clients that need to access their own far apart PA regions, and once you open a new row you’re unlikely to need the previous one. So as an example, maybe I have a texture at address 0 that I (mainly) linearly go through and bring into the cache, so that I’m unlikely to need previous data. And at the same time I have a render target located 32MB after the texture that I write to semi randomly, and I don’t want it to interfere with rows that the texture reads are using.
Banks vs Bank Machines
Just to be clear, the number of banks != the number of bank machines in the controller. For an example of how this can affect performance, I’m going to directly quote Xilinx:
Increasing the number of Bank Machines can improve the efficiency of the design. For example, if a traffic pattern sends writes across a single row in all banks before moving to the next row (writes to B0R0, B1R0, B2R0, B3R0 followed by writes to B0R1, B1R1, B2R1, B3R1), five bank machines will provide higher efficiency than 2, 3 or 4. Requests for each bank in Row0 can be assigned to the first four Bank Machines. When the request comes in for Row1, requiring a Precharge/Activate, the 5th Bank Machine can be assigned this request while the other Bank Machines complete any pending requests
In my controller, I left the default number of bank machines at 4, but that’s just because I haven’t done any profiling yet to see if my memory access patterns could benefit from additional bank machines.
Generating The Controller
Digilent is kind enough to provide MIG-loadable project files containing the DDR parameters, however MIG import is horribly broken. It will do things like ignore the clock period defined in the project and just set something else. Therefore it’s probably best to just manually enter everything yourself. You might even learn something along the way. You will still need the UCF file containing the pin constraints for the board. It can be downloaded here.
With that downloaded, go ahead and open the Memory Interface Generator in the IP Catalog. On this first screen you’ll want to select Create Design (because we’re not importing a project), set a component name for your controller, set the number of controllers to 1, and make sure that AXI4 is unchecked. Hit next, and enter in the FPGA part number, which should be xc7a100t-csg324. Hit next again and select DDR3 SDRAM.
There is quite a bit to enter on the next page. The clock period should be set to 3000ps, or 333.33MHz. Set the PHY to controller ratio to 4:1, the memory part to MT41K128M16XX-15E, the memory voltage to 1.35v, and the data width to 16. Ordering should be normal, number of bank machines is 4, and enable the data mask if you think you’re going to need it.
On the next page, set the input clock period to 6000ps (166.666MHz), the read burst type to sequential, and output driver impedance control and RTT to RZQ/6. It’s up to you if you want to use a chip select pin and what address mapping you want to use.

The above page is where stuff starts getting interesting. First up, we need to choose configurations for the system clock and reference clock, with options like single-ended, differential, and no buffer. Differential is for differential pairs, single ended is useful for when we directly connect to an external clock pin, and no buffer is probably what you want if you are deriving your clocks from a clocking wizard (like me!). This naming always threw me off, because “no buffer” sounds like it can’t be used with clock buffers. Rather it means there is no clock buffer, so feel free to use your own. So let’s just say we set these both to no buffer and move on. It will save you having to track down obscure clock backbone errors in implementation.
System reset polarity can be anything you want, as long as you remember what you chose later when we hook up the controller. Maybe its just best leave it as its default, active low. Debug signals should be off, unless you somehow really need it. Then turn on internal vref and IO power reduction. Finally, XADC instantiation is turned off in the suggested settings, but what do they know?! Go ahead and enable it unless you are using the XADC block somewhere else in the design. Click next to go to the next page and set the impedance to 50Ω.
We’re almost done now. On the next screen, choose Fixed Pin Out, and hit next. Then click Read XDC/UCF and browse to the UCF file you previously downloaded. Click on the validate button to validate, and you should be greeted with a popup saying the current pinout is valid. Here’s a funny story. If you had imported the Arty project instead of entering all the above settings manually, this step would fail with alot of very scary sounding warnings. Aren’t you glad you did it all manually?
The final config screen asks you to select pins for sys_rst, init_calib_complete, and tg_compare_error. Honestly, this screen is for fancy people who want to hook things up to actual pins for some reason. Leave all of these unconnected, and we’ll hook them up to logic later. After this, its a bunch of summary screens, disclaimers clearing Xilinx of any liability if your device explodes, and accept prompts. Blow through all these and you will have yourself a shiny new memory controller.
Using The Controller
So you have a controller generated, but what now? Hooking it up is easier than you might think. Note that this is just for synthesis, as the process for simulation is quite a bit more complicated, and will be explained later in this post.
Hooking It Up
Go to your top module, and add the following DDR3 signals to your module ports.
parameter DQ_WIDTH = 16;
parameter DQS_WIDTH = 2;
parameter CS_WIDTH = 1;
parameter ROW_WIDTH = 14;
parameter DM_WIDTH = 2;
parameter ODT_WIDTH = 1;
module jpu2_top_module(
input wire logic CLK100MHZ,
input wire logic [3:0] sw,
output wire logic [3:0] led,
input wire logic [3:0] btn,
// HDMI
output wire logic [3:0] hdmi_out_p,
output wire logic [3:0] hdmi_out_n,
// DDR3 signals
inout wire logic [DQ_WIDTH-1:0] ddr3_dq,
inout wire logic [DQS_WIDTH-1:0] ddr3_dqs_n,
inout wire logic [DQS_WIDTH-1:0] ddr3_dqs_p,
output wire logic [ROW_WIDTH-1:0] ddr3_addr,
output wire logic [3-1:0] ddr3_ba,
output wire logic ddr3_ras_n,
output wire logic ddr3_cas_n,
output wire logic ddr3_we_n,
output wire logic ddr3_reset_n,
output wire logic [1-1:0] ddr3_ck_p,
output wire logic [1-1:0] ddr3_ck_n,
output wire logic [1-1:0] ddr3_cke,
output wire logic [(CS_WIDTH*1)-1:0] ddr3_cs_n,
output wire logic [DM_WIDTH-1:0] ddr3_dm,
output wire logic [ODT_WIDTH-1:0] ddr3_odt);
The clever among you will notice that normally the names of signals in your top level module come from your constraints file, but none of these DDR3 signals are in Arty-A7-100-Master.xdc. This is because MIG generates a second secret constraints file that isn’t added to the project. I named my controller ddr3_native_controller, and so the constraints file would be something like ddr3_native_controller.xdc, and its stored around jpu2.gen\sources_1\ip\ddr3_native_controller\ddr3_native_controller\user_design\constraints\.
The other thing to note is those params at the top. Where they come from will make a bit more sense once we get to the section on simulation. But for now, its fairly safe to use them as-is if you stick to the controller settings outlined above.
To actually instantiate the controller, just do this
localparam DATA_WIDTH = 16; localparam PAYLOAD_WIDTH = DATA_WIDTH; localparam nCK_PER_CLK = 4; localparam APP_DATA_WIDTH = 2 * nCK_PER_CLK * PAYLOAD_WIDTH; localparam APP_MASK_WIDTH = APP_DATA_WIDTH / 8; localparam ADDR_WIDTH = 28; // DDR3 controller app signals logic [(2*nCK_PER_CLK)-1:0] app_ecc_multiple_err; logic [(2*nCK_PER_CLK)-1:0] app_ecc_single_err; logic [ADDR_WIDTH-1:0] app_addr = 0; logic [2:0] app_cmd = 0; logic app_en = 0; logic app_rdy; logic [APP_DATA_WIDTH-1:0] app_rd_data; logic app_rd_data_end; logic app_rd_data_valid; logic [APP_DATA_WIDTH-1:0] app_wdf_data = 0; logic app_wdf_end; logic [APP_MASK_WIDTH-1:0] app_wdf_mask = 0; logic app_wdf_rdy; logic app_sr_active; logic app_ref_ack; logic app_zq_ack; logic app_wdf_wren = 0; logic sys_rst = 0; // UI clock is returned by the UI, and is 1/4 the memory interface clock // 325MHz / 4 = 81.25MHz logic ui_clk; logic [11:0] device_temp; ddr3_native_controller u_ddr3_native_controller ( // Memory interface ports .ddr3_addr(ddr3_addr), // output .ddr3_ba(ddr3_ba), // output .ddr3_cas_n(ddr3_cas_n), // output .ddr3_ck_n(ddr3_ck_n), // output .ddr3_ck_p(ddr3_ck_p), // output .ddr3_cke(ddr3_cke), // output .ddr3_ras_n(ddr3_ras_n), // output .ddr3_we_n(ddr3_we_n), // output .ddr3_dq(ddr3_dq), // inout .ddr3_dqs_n(ddr3_dqs_n), // inout .ddr3_dqs_p(ddr3_dqs_p), // inout .ddr3_reset_n(ddr3_reset_n), // output .init_calib_complete(init_calib_complete), // output .ddr3_cs_n(ddr3_cs_n), // output .ddr3_dm(ddr3_dm), // output .ddr3_odt(ddr3_odt), // output // Application interface ports .app_addr(app_addr), // input .app_cmd(app_cmd), // input .app_en(app_en), // input .app_wdf_data(app_wdf_data), // input .app_wdf_end(app_wdf_end), // input .app_wdf_wren(app_wdf_wren), // input .app_rd_data(app_rd_data), // output .app_rd_data_end(app_rd_data_end), // output .app_rd_data_valid(app_rd_data_valid), // output .app_rdy(app_rdy), // output .app_wdf_rdy(app_wdf_rdy), // output .app_sr_req(1'b0), // input .app_ref_req(1'b0), // input .app_zq_req(1'b0), // input .app_sr_active(app_sr_active), // output .app_ref_ack(app_ref_ack), .app_zq_ack(app_zq_ack), // output .ui_clk(ui_clk), // output .ui_clk_sync_rst(rst_from_ui), // output .app_wdf_mask(app_wdf_mask), // input // System Clock Ports .sys_clk_i(sysclock_166MHz), // input // Reference Clock Ports .clk_ref_i(refclock_200MHz), // input //.device_temp_i(device_temp_i), // input .device_temp(device_temp), // output .sys_rst(sys_rst) // input );
Clocking
The controller takes in two clocks and outputs one. The input clocks are a 200MHz reference clock, and a 166.666MHz system clock, both of which can be generated by a Vivado clocking wizard. These are refclock_200MHz and sysclock_166MHz in the above code. The output clock is ui_clk, and is the clock that the user interface part of the controller runs on. So any logic you have that drives controller signals should be clocked on the positive edge of this depressingly slow 81.25MHz clock.
Assuming you chose for the reset signal to be active low, you have to hold sys_rst low for a minimum of 200 nano, before bring it high again. You can do this any way you want, but I usually do something silly like this
// reset delay is something like 200000 pico (or 200 nano) // so 100MHz clock has a period of 10 nano // and so we can just hold it low for 20+ clocks logic [4:0] reset_cnt = 1; always_ff @(posedge CLK100MHZ) begin : DDR_RESET // count up until we wrap around to zero, and then stay there reset_cnt <= reset_cnt + |reset_cnt; sys_rst_n <= ~|reset_cnt; end : DDR_RESET assign sys_rst = RST_ACT_LOW ? sys_rst_n : ~sys_rst_n;
Paths
There are two different paths to the controller: one for writing commands and another for adding the data you want to write to memory. These paths are (semi) independent in that you can add write data before or at the same time as you add the corresponding command. You can also add write data after you add the command, but it must be within two clocks of adding the command.
Command Path
The command path deals with writing commands, and any signals that are common to reads and writes. To issue commands, set the command number, the address, and assert app_en. This path can randomly become unavailable as the controller performs various internal functions, so you have to always check app_rdy the clock after setting your data to know if you need to continue holding or if the command was accepted. To make this a bit clearer, here is a sample waveform to illustrate.

In the above example, app_rdy transitions from 1 to 0 on the exact same clock as a write command is being added. If we were to sample app_rdy on that clock, we’d get the old value (1) and mistakenly think the command would be accepted. Therefore we have to start checking app_rdy the clock *after* we set command data.
Signals
app_rdy: output, indicated whether a command could have been accepted the previous clock app_in: input, indicates to the controller that we're adding a command app_cmd: input, 1 for reads and 0 for writes app_addr: input, the address of the read or write command we are adding ui_clk_sync_rst: output, active low signal indicating the UI is ready to use init_calib_complete: output, active high signal indication DDR3 calibration is complete
Write Data Path
The write data path is basically a FIFO holding 128 bit data to be written to memory. Like the command path, it also has a signal to indicate when data has been successfully added, but unlike the command path’s app_rdy which can ho high and low at random times, app_wdf_rdy is basically there to tell you if the write data FIFO is full, and won’t suddenly go low unless you add data. This makes it a bit easier to work with.
Signals
app_wdf_rdy: output, indicates the write data FIFO isn't full, and new data can be added app_wdf_wren: input, write data FIFO write enable app_wdf_data: input, the 128 bit write data to be added to the FIFO app_wdf_mask: input, per-byte write enable mask. Active low app_wdf_end: input, must always be tied to app_wdf_wren, despite what the incorrect docs say
This explains the timing requirements. Because write data is just added to a FIFO, it can be added before or together with a write command. When a write command is encountered, a few clocks later the write path will get the data to be written from the write data FIFO. Like I said before, its possible to add the write data up to two clocks after the write command, but I’ve not tried that before and it feels like you’re asking for trouble.
Performance

Simulation
This was initially a bit confusing for a dumb reason. With most other IP, you set it up, generate it, instantiate it, and it all just works both for synthesis and for simulation. The memory controller is a bit different because controller != memory. You need both the controller IP *and* the DDR model for it to work, or else the controller will sit around forever waiting for calibration. Sadly the info on how to make this work isn’t easy to find (or I am garbage at searching)

The first step is to right click on the controller IP in the sources pane, and go to Open IP Example Design. Save it somewhere, and go to that directory in explorer. You’ll see a subdirectory called imports, which you’ll want to copy and paste to the root directory of your project.
Some tutorials I have seen say it’s ok to only copy some of the RTL files, but it’s probably safer to just copy everything and then remove what you don’t need. Next, add wiredly.v, ddr3_model.sv, and sim_tb_top.sv to your project’s simulation sources. You may need to add some of the other sources as well, if you get errors about undefined modules. Then, set sim_tb_top to be the new top module for simulation.

We’re almost done. Essentially what we’re going to do is to let that new top module from the sample design handle all the DDR stuff for us, but inside of it we instantiate our old top module and pass the relevant DDR signals. Search sim_tb_top.sv for the section that says FPGA Memory Controller , and just below you’ll see a module called example_top being instantiated. Replace example_top with the name of your previous simulation top (sim_top in the above image), and modify the module to take the DDR signals passed in from sim_tb_top. So my sim_tb_top.sv now looks like this
// this is sim_tb_top.sv. Its the file that came from the generated reference design.
// it used to instantiate a module called example_top, but I replaced that with my sim_top
//===========================================================================
// FPGA Memory Controller
//===========================================================================
sim_top u_ip_top(
// DDR signals here
// this is in sim_top.sv
// it's my old top module before I made sim_tb_top the new top module.
// I also modified it to add all the DDR signals
module sim_top(
// DDR3 signals from sim_tb_top
inout wire logic [DQ_WIDTH-1:0] ddr3_dq,
inout wire logic [DQS_WIDTH-1:0] ddr3_dqs_n,
inout wire logic [DQS_WIDTH-1:0] ddr3_dqs_p,
output wire logic [ROW_WIDTH-1:0] ddr3_addr,
output wire logic [3-1:0] ddr3_ba,
output wire logic ddr3_ras_n,
output wire logic ddr3_cas_n,
output wire logic ddr3_we_n,
output wire logic ddr3_reset_n,
output wire logic [1-1:0] ddr3_ck_p,
output wire logic [1-1:0] ddr3_ck_n,
output wire logic [1-1:0] ddr3_cke,
output wire logic [(CS_WIDTH*1)-1:0] ddr3_cs_n,
output wire logic [DM_WIDTH-1:0] ddr3_dm,
output wire logic [ODT_WIDTH-1:0] ddr3_odt,
// clocks. todo: these need to be generated
input wire logic sys_clk_i,
input wire logic clk_ref_i,
// misc
input wire logic [11:0] device_temp_i,
output wire logic init_calib_complete,
wire logic tg_compare_error,
input wire logic sys_rst);
// your code here!
endmodule
And that’s it! Those signals can be hooked up to your DDR3 controller, and you should be in business. There are three things to note, though. First of all, simulation can take a Very Long Time. Like minutes or more of wall clock time can pass before DDR calibration finishes, so be prepared to wait unless you disable calibration. Second, you’ll notice I have input ports for sys_clk_i, clk_ref_i, and sys_rst. The top level simulation generates these signals for you as a convenience, so you’re free to use them in simulation, but it’s probably a better idea to just use what’s described in the clocking section above. And finally, you’ll notice I don’t have any of those module parameters such as DQ_WIDTH, ROW_WIDTH, and CS_WIDTH that you’ll see in your version of the files. So that I can use them all over, I pulled all the parameters into a header file (ddr3_params.vh) that is included anywhere it’s needed. I suggest you do the same.
Interfacing With Native Directly
Signals and Flow
It’s probably useful to begin with looking at the general flow of native mode
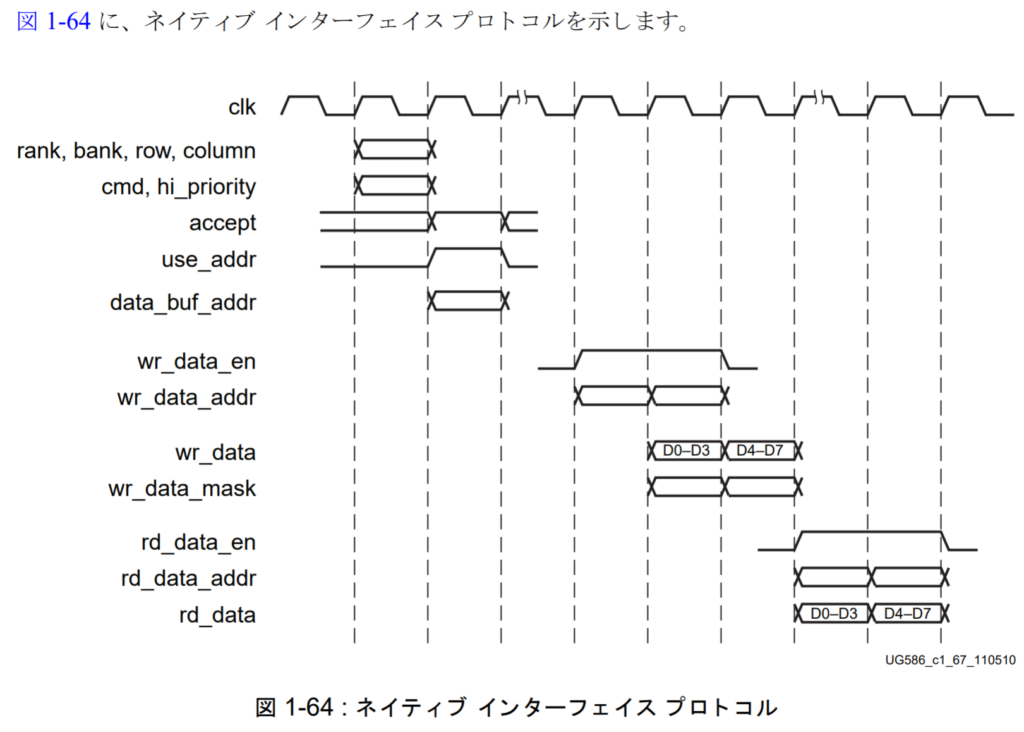
The timing diagrams are fairly self explanatory, but I’ll go over the general usage anyway. To add a command, on clock N set the command data. Command data is the command itself, priority bit, data_buf_addr, and the address in {rank, bank, row, column} form. This is the first difference between native and UI. When creating the controller, you chose a mapping from user address to bank, row, and column, and the address encoding was handled by the UI layer. But with native you have to manually specify these yourself. Next, on clock N+1, assert the use_addr signal to indicate a request wants to be added. If accept was asserted, then use_addr can be safely deasserted on clock N+2.
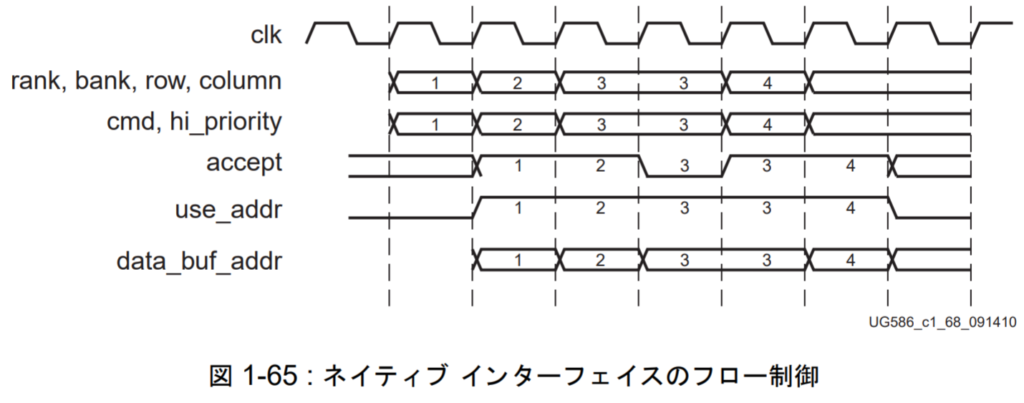
図1-65 shows the flow for adding multiple simultaneous commands. Assuming the command data is set on clock N, you still assert use_addr on clock N+1. If accept is high at that time, then it’s OK to move on to the next command data. You can see this when the command data transitions from 1 to 2 on clock N+1. Things get more interesting on clock N+3. use_addr is asserted and the command data wants to transition from 3 to 4, but it can’t because accept is low. Therefore the command data must remain stable until accept goes high.
The biggest difference between UI and native has to do with data_buf_addr. Because the native layer can reorder requests for efficiency, it needs a way to signal to the user design which request is being referenced. For writes, data_buf_addr might be an index into a user buffer that stores the data to be written. For reads, it might be an index into a user buffer where we will store data returned from memory for reordering.
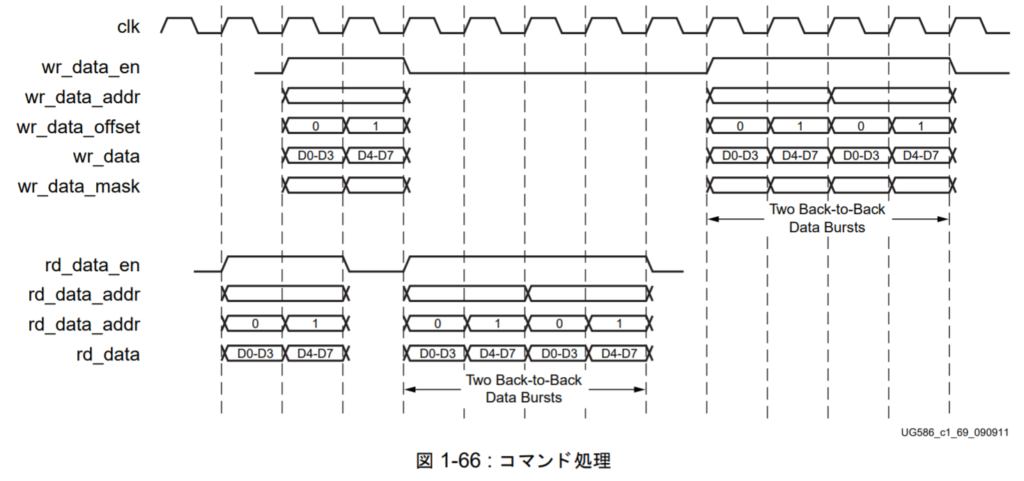
This is illustrated in 図1-66. For writes, wr_data_en is a signal from the native layer that indicates it is pulling the write data for a previously added write command. wr_data_addr will be the same as the data_buf_addr we added with the command data. You’ll notice that while the write data is 128 bits, write data D0~D3 (the first 16×4=64 bits) is read from the user buffer on the first clock, and D4~D7 (the last 64 bits) on the next clock. To make this easier to handle, the native layer also provides wr_data_offset, which will be 0 during the first 64 bits and 1 during the last 64 bits. When wr_data_en is high, it’s your job to take wr_data_addr and wr_data_offset and use them to look up the write data for the command. This write data is used to drive wr_data.
Reads function similarly. rd_data_en indicates that the native layer is returning read data to you. rd_data_addr is an echo of the data_buf_addr you added with the read command, rd_data_offset will be 0 for the lower 64 bits and 1 for the upper 64 bits, and rd_data is the 64 bits of read data being returned from memory. Once you receive the data, its up to you to reorder it if that’s something you care about.
Corrections
First of all, a confession: I probably should have said this earlier, but while the above descriptions do match the timing diagrams shown in the docs, they don’t match the actual Arty A7 DDR3 configuration. The diagrams assume a burst length of 4, meaning data is returned 16×4=64 bits at a time. But we have BURST_LENGTH set to 8, or 16×8=128 bits, meaning we only need one read/write per request, and both rd_data_offset and wr_data_offset will always be zero. To be fair to Xilinx, this is called out in the docs, as the description of wr_data_offset specifically states
このバスは、バースト長の処理に1サイクル以上が必要なときに使用します
You can see all this in the waveform below.
I should also mention there a few confusing errors in 図1-66. First of all, rd_data_addr is listed twice. The second one obviously should be rd_data_offset. Next, the way the write timing is shown is incorrect. It seems to imply that you are supposed to provide the write data on the same clock that the system tells you the buffer address to pull it from. Surely that can’t be right. 図1-64 seems to get it right, since wr_data_en and wr_data_addr are provided on clock N, and you’re expected to provide the corresponding write data on clock N+1. This can be seen in the following waveform
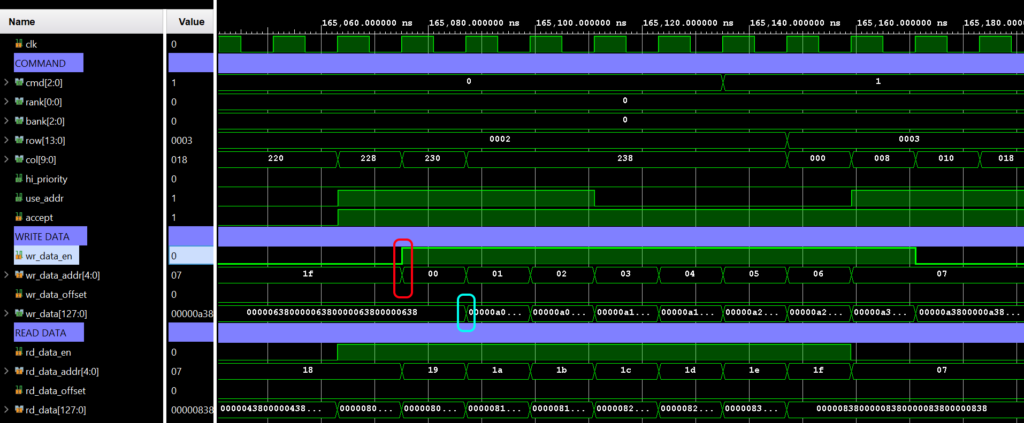
Here you’ll see wr_data_en go high the same clock that wr_data_addr comes (red circle). And it one clock after this that the user buffer provides the data to be written to memory (blue circle).
How The UI Layer Does It
The UI provides a (possibly overcomplicated?) sample implementation for the read and write buffers. These are located at user_design\rtl\ui\mig_7series_v4_2_ui_rd_data.v and user_design\rtl\ui\mig_7series_v4_2_ui_wr_data.v respectively. I recommend taking a look through these to see what they are doing, or at least reading the extensive comments for a pretty good description of how they work. Actually, while you’re there, check out all the source for the IP. Everything is in there, even PHY.
As a bit of starting advice, before you go modifying the UI, try setting the controller data ordering to STRICT. Much of the UI latency comes from read reordering, which is turned off in by the following line
if (ORDERING == "STRICT") begin : strict_mode assign app_rd_data_valid_ns = 1'b0; assign single_data = 1'b0; assign rd_buf_full = 1'b0; reg [DATA_BUF_ADDR_WIDTH-1:0] rd_data_buf_addr_r_lcl; wire [DATA_BUF_ADDR_WIDTH-1:0] rd_data_buf_addr_ns = rst? 0 : rd_data_buf_addr_r_lcl + rd_accepted; always @(posedge clk) rd_data_buf_addr_r_lcl <= #TCQ rd_data_buf_addr_ns; assign rd_data_buf_addr_r = rd_data_buf_addr_ns; always @(rd_data) app_rd_data = rd_data; always @(rd_data_en) app_rd_data_valid = rd_data_en; always @(rd_data_end) app_rd_data_end = rd_data_end;