このサイトのコンテンツは個人の意見で会社を代表しません
概要
Dokukon (独身コンピューター), also known as Hitokon (一人コンピューター)Bocchikon, and any other name that implies the opposite of ファミコン, is a 18 bit retro console mainly made in a weekend as part of a 48 hour console jam. It tries to stick to clock speeds that would have been plausible in the 16-bit era, with a few notable exceptions described in later sections.
The general design philosophy can be summarised as: I hate CPUs, and want to do everything I can to minimise CPU involvement in everything. The audio system uses command buffers that can play complex songs just by writing a single MMIO register. The scatter/gather pattern DMA is designed to transfer data to and from different source and destination patterns to avoid CPU loops. The start address of palette index and colour writes encodes a pattern so that every CPU write updates the destination address to the next location in the pattern.
Parts Used
- Arty A7 100T board
- HDMI PMOD
- AMP3 Audio PMOD
- Famicom Controller
The Arty can be purchased from Digilent here. The AMP3 PMOD is also from Digilent, and is sold here. Finally, the Famicom controller is just a regular Famicom controller with the connector cut off, and wired to PMOD-pluggable pins. See below for more info.
Scanout
This is the most major departure from the 16-bit era clock speed goal. The screen is fixed at 640×480 @ 60Hz, for which the HDMI spec requires a 25.175MHz pixel clock and a 251.75MHz TMDS clock. The HDMI block is responsible for signalling the GPU both when new scanlines start, and N clocks before a scanline starts, where N is the latency of HDMI => GPU messages. The GPU then adds colours to a pixel colour FIFO which scanout then reads from and displays.
Audio
Audio output is fixed at 16 bits per channel, two channel stereo, and a 24,000Hz sample rate. This is driven by a 768KHz bit clock, and an MCLK of 6.144MHz that drives the audio logic. Technically it could be clocked much lower, but good luck getting a PLL/MMCM to generate a clock in the kilohertz range
Audio is programmed via GPU-like command buffers stored in audio RAM. There are per-channel CPU-accessible MMIO registers responsible for setting the command buffer address, pausing and unpausing the audio, and setting volume, with more registers currently being added. The currently available commands are
- square wave: Play a note from C3 to B5, for a length of time between a whole note and sixteenth note, including dotted
- set BPM: set the channel BPM. Supported range is 50 to 177
- rest: insert a rest. Supports all note lengths supported by square waves
- set label: write an initialisation value to one of the four labels
- conditional jump: takes a label number, condition, decrement flag, and jump offset. The command looks at label [0..3] and tests it for a condition, optionally decrementing the label. This can be used for conditional jumps, unconditional jumps, and repeating a section of music a number of times
Future support is planed for setting note decay and fadeout, PCM data, triangle waves, and noise
Synchronisation and loops/repeats are achieved through labels. To synchronise two channels, you can have one wait on a label that the other one writes. To implement loops and repeats, use a label write to set the repeat count, and then use a conditional jump with label decrement.
GPU
The GPU is designed around sprites and tile graphics, with a max of 128 sprites, of which 64 are displayable per scanline. The tile size is 32×32, and so a 640×480 screen becomes 20×15=300 background tiles.
State Machines
The GPU is divided into three state machines: background tile processing (BG), sprite search, and foreground sprite processing (FG).
GPU processing starts when HDMI signals the GPU to start a new scanline, which runs the BG processing and sprite search state machines in parallel. Sprite search is pretty simple. It looks at all 128 sprites for the first 64 that intersect the current scanline, and adds them to a list. BG processing is a bit more involved. It looks at each pixel in a scanline and works out what BG tile it lives in. It then looks up that tile’s index in GPU RAM, and uses that index to fetch graphics data for the pixel from graphics tile ROM. The graphics tile data is then used as an index into a colour palette to get the background pixel colour. Lastly, it determines the final colour by pulling from the FG sprite FIFO to see if there is a sprite overlapping this pixel and whether its transparent. This final colour is added to an HDMI FIFO for scanout to consume.
BG and FG both need to share a read port for graphics tile ROM, and so they can’t run at the same time. So when BG processing reads the final pixel’s data from the ROM, it then signals FG sprite processing to begin. FG processing does a parallel reduction of the 64 intersecting sprites found by the sprite search pass, and finds the first one to intersect the current pixel. It then looks up that sprite’s pixel in graphics tile ROM to get it’s palette index, and to see if it’s transparent. Note that FG must always run one scanline ahead of BG so that BG processing has the expected data in its FG FIFO.
The GPU is also responsible for signalling the CPU when a new scanline is started, when BG processing finishes, and when FG processing finishes. The CPU can then poll on an MMIO status register to wait for a specific part of a scanline to finish. This is useful for when you only want to change tile indices, and need to wait for BG processing but not FG processing to finish for the current scanline. Or maybe you want to change sprites for the next scanline, and therefore need to wait for FG processing to finish. There is also logic in there to signal the CPU as early as possible, to make up for the round trip latency of the CDC FIFO used to signal the CPU, and the time it takes for a CPU register write to be seen by the GPU.
Palettes
Currently there are 8 background palettes with 8 colours each. The 32×32 background tiles are grouped into 64×64 supertiles, where each tile in a supertile uses the same palette. This means a screen becomes 10×8=80 supertiles, which is alot of data for the CPU to update. To make it a bit more convenient to update sparse indices without the CPU constantly changing the destination address, I encode the address in a similar way to what I use for DMA.
address = dest index (7b), dest X inc (3b), dest Y inc (2b), writes per row (4b)
Just like DMA, every time a new palette number is written, the destination address is automatically changed according to the pattern. And just like the DMA encoding, this allows you to update a linear array of indices, a sparse block of indices, a row of indices, or a column.
There is a similar trick when updating the colours in the palettes. The start address encodes start palette, start colour withing the palette, num colours per palette to update, and colour increment. So you could start at palette 2, and update colours 1, 4, and 7 in all subsequent palettes without ever the CPU changing address.
CPU
The CPU runs at 10MHz, and has a three stage pipeline with no hazards. It reads 16-bit instructions from a 4096 deep instruction memory ROM bank.
ISA
The CPU utilises a RISK ISA. This is not a typo or an acronym, I just think you’re taking a big RISK if you expect it to correctly execute instructions. It currently has the following instructions
- add/sub
- shift
- bitwise: contains a 4 bit function field that specifies AND, OR, XOR, NOT
- popcnt
- mov 8-bit literal low
- mov reg
- insert 8-bit literal high
- load
- pop
- pack
- unpack
- jump
- branch if zero
- branch if not zero
- branch if carry
- branch if negative
- call
- return
- store
- push
- compare: compare register with register, or register with literal
- nop
Fun facts:
All branch and jump instructions have two forms: one where the instruction encodes a literal offset, and another where it encodes register number that holds the offset. The instruction after any PC-modifying instruction is considered a branch delay slot.
Mov 8-bit literal low is usually used in conjunction with insert 8-bit literal high to build 16-bit literals. The low mov instruction will write 8 bits to the destination’s LSB8, and zero out the MSB8. Insert leaves the LSB8 as it is, and inserts 8 bits to the MSB8.
And then there is pack/unpack. I wanted a fast way to extract some bits from a field in a register, update the value, and insert the new value back in, but there weren’t enough bits available for the pack. The initial solution was to have unpack set an internal insert mask that pack then uses when reinserting the bits. This mask persists as long as you don’t do another unpack, and so it can be used for multiple packs in a row. I am not 100% in love with this, and am currently considering other solutions such as implicit pairs of aligned registers to save bits for this instruction.
Memory System
All ROMs and RAMs are grouped into the appropriate sounding but vaguely named Memory System. It is also home to the CPU-accessible MMIO registers used to program other bits of the hardware. The CPU accesses these via load and store instructions to four aperatures.
CPU accessible apertures
- MMIO: RW, aperture for MMIO registers
- RAM: RW, aperture for CPU accessible RAM
- ROM: RO, aperture for reading from ROM
- tile indices: RW, currently unused, but eventually shares a GPU RAM write port with DMA
So for example, a write to MMIO might look like this
mov r0, kMmioRegGpuSetSpriteNum mov r1, #0 store r1, r0, kApertureMmio, #0
The 16 bits of address and 2 bits of aperature form a 18-bit address. The memory map then becomes:
aper offs CR CW GR GW DR DW 0x00_0000 1 1 0 0 0 0 <= start of RAM 0x00_FFFF 1 1 0 0 0 0 <= end of RAM 0x01_0000 1 0 0 0 1 0 <= start of general ROM data 0x01_FFFF 1 0 0 0 1 0 <= end of general ROM data 0x02_0000 1 1 1 1 0 0 <= start of MMIO regs 0x02_FFFF 1 1 1 1 0 0 <= end of MMIO regs 0x03_0000 0 0 1 0 0 0 <= start of gfx tile data ROM 0x03_FFFF 0 0 1 0 0 0 <= end of gfx tile data ROM (131,072 bytes, 341 tiles, 1.14 screens) (memory map doesn't include internal GPU RAM)
RAMs and ROMs
The memory system encompasses the following RAM and ROM banks:
- CPU RAM: 16-bit RAM accessible to the CPU
- CPU ROM: 2048 deep ROM of 18 bit halfwords. CPU can only access the LSB16 of each halfword
- GPU RAM: 1024 deep RAM of 18 bit halfwords. Each halfword stores two 9-bit indices into tile ROM
- GPU graphics tile ROM: 65,536 deep ROM of 18-bit halfwords
The sizes need a bit of clarification. A graphics tile is a 32×32 pixel block of image data, where each pixel is a 3-bit palette index. So a single 18-bit halfword stores palette indices for six pixels. So to store one row of a 32×32 tile requires six halfwords (with four bits wasted at the end), and a whole tile is 32×6 = 192 halfwords per tile. A 640×480 screen is covered by 20×15=300 tiles, and so one screen worth of data would require 57,600 halfwords. Graphics tile ROM is 65,536 deep, so we can store about 1.14 screens worth of tiles. This isn’t great, and I plan to improve it, but for the time being do plan on reusing graphics tiles alot.
GPU RAM needs to store 9-bit indices for the 300 background tiles. This works out to 150 halfwords, and yet the RAM is 1024 deep. This is because the smallest BRAM primitive on the board is 18kbit. I should probably look into finding other uses for the unused memory.
Finally, CPU ROM has a bit of a dual nature. It’s 18-bits wide, but the only client that can access the whole 18 bits is DMA. Only the LSB16 of each halfword is visible to the CPU. I wish I had a great excuse for why this is, but the jam was only 48 hours long and I jumped into making the CPU before realising everything else in the system should be 18 bits.
Gather/Scatter Pattern DMA
DMA is how background graphics tile indices are transferred from ROM to the GPU, and is clocked with the GPU clock. There are three MMIO registers used to program and kick off DMA transfers
- DMA config reg 0
- src start addr: 12 bits, source start, [0..4095] tiles
- num Y tiles: 4 bits, number of tiles to transfer in the Y direction, [1..15]
- DMA config reg 1
- dest start addr: 9 bits, destination start, [0..299] tiles
- num X tiles: 5 bits, number of tiles to transfer in the X direction, [1..20]
- src X inc MSB2: 2 bits, the MSB2 of the source X increment
- DMA config reg 2
- src X inc LSB3: 3 bits, source X direction increment, [0..20] tiles
- src Y inc: 4 bits, source Y direction increment, [1..15] tiles
- dest X inc: 5 bits, destination X direction increment, [1..20] tiles
- dest Y inc: 4 bits, destination Y direction increment, [1..15] tiles
Writing to that final register is what initiates the DMA transfer. This can be used to do a few useful things. First, you can copy data linearly, or copy a packed block of indices to a packed area in GPU RAM. You can also copy a packed block of indices to a sparse area in GPU RAM, and vice versa. Finally you can splat a single source index into either a packed or sparse area in GPU RAM. Here is an example from the SDK katakana sample
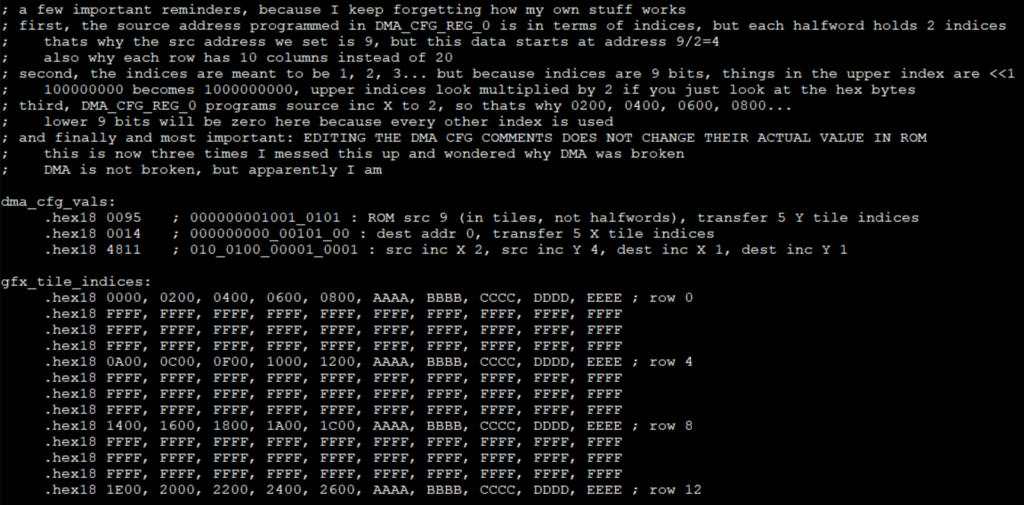
Finally, there is a 16-deep DMA request queue. This was supposed to be a quick hack get some of the functionality of DMA chains. However the DMA status MMIO registers aren’t currently hooked up, so be careful not to overflow the FIFO. I will have to fix this eventually.
Controller
The controller was “designed” to feel “familiar” to retro gamers. It has a d-pad, two buttons, plus start and select.

The latest controller data is sampled at roughly 625KHz. It’s probably safe to clock it a bit higher, but the japanese datasheet for the shift register is not very clear on the maximum clock speed when voltage is 3.3v, so I kept it under 1MHz just to be safe. The CPU can query the latest controller data at any time via MMIO register. The Vivado constraints for PMOD port JD are set up as the following

Dev Environment and IDE
Current system requirements are
- high tolerance for crap
- low expectations
- Windows10 64 bit
Because you can’t make games without a proper IDE, I decided to write one using internet snippets of C#, a garbage language with no redeeming value. The theme I am going for is making people long for the days of PS2 CodeWarrior, if you know what I mean. Currently you can build code and data, verify and connect to devkits, and upload executables and data to them. Eventually I’ll add sound and graphics editors
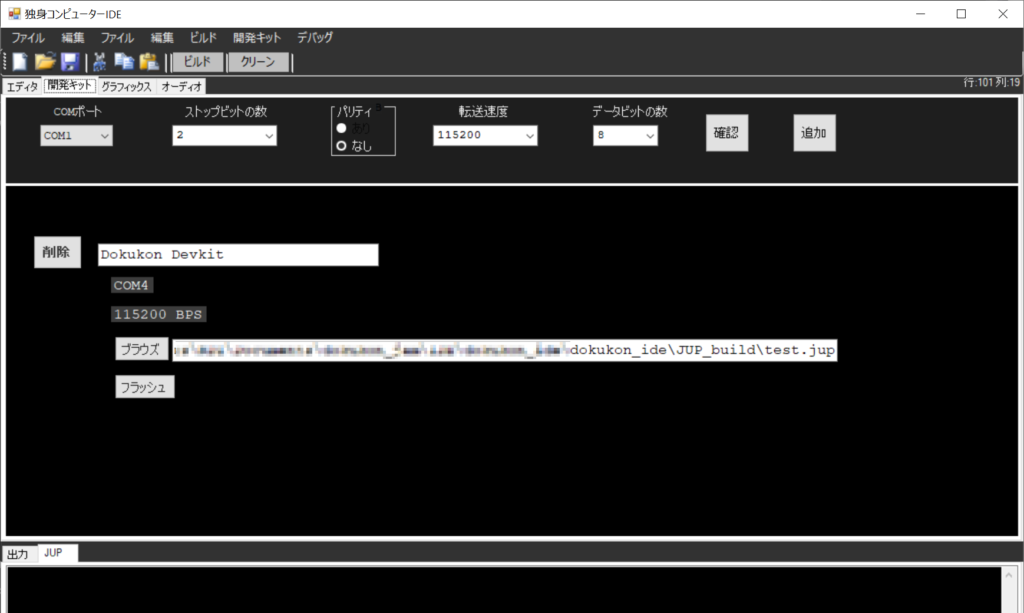
Host Target Comms
Host target communication is done over UART, with 8 data bits, 2 stop bits, and no parity. Parody, on the other hand, is enabled for this entire project. Host sends the target update files, consisting of
- global update header
- section header (18 bit one-hot)
- section checksum (18 bit XOR)
- num 18 bit halfwords in the data payload
- data payload (18 bits x num_halfwords)
- additional sections (section header + checksum + payload)
- global update end (18’b0)
The first four section headers (0001, 0010, 0100, 1000) correspond to the four flashable ROMs: code, data, graphics tile, and audio. A write to any of these ROMs will trigger a devkit reset, and light up the corresponding colour LED on the Arty. Yellow means a particular ROM will be updated, green means that ROM’s update succeeded, and red means the ROM data failed the checksum test.
Other section headers include confirm (send a message to the host when the IDE 確認 button is pressed), LED on (light up some LED pattern), and eventually debugger messages should I ever decide to try and make one.
Special Thanks
Extra special thanks to Rupert Renard, Mike Evans, and the rest of hardware twitter for being so generous with your advice and patient with my stupid questions. Thanks to Colin Riley for the expertly crafted HDMI PMOD that made HDMI possible. Also shout out to Ben Carter (yes, that Ben Carter. The Super Famicom ray tracing one) and Laxer3A for working on what is arguably two of the coolest projects out there, and inspiring me to keep pushing.
FAQ
why 18 bits? Two reasons. First, with ECC disabled, a block RAM byte is 9 bits. This seemed pretty useful at the time, so I just designed everything around that and the numbers worked out really well. Second and most important, Jake Kazdal thinks he’s so cool for calling his company 17bit, and I just felt like I needed to one-up him.
Console X does it this way. Why don’t you? Because its more fun to try and make up your own weird ways to do things without copying others. Sometimes you come up with the same solution others did, and sometimes you make something worse. All that matters is you have fun in the process!
How do I become a registered developer? I dunno, sign an NDA and pay a developer fee to The City Of Elderly Love animal shelter?
Is everything rigorously verified/validated, and confirmed working? LOLZ no. I do have lots of SVA asserts, though, if that makes you feel better.
Will the Madden release for this at launch have the full franchise mode or only season + exhibition games?
Thank you for your inquiry into dokukon development. Unfortunately, we have CRTs against predatory monetization, and so such a game would never pass CRT check. If you like the game that much, I will release a clone called Maddening incorporating everything I know about american football. Which is precisely nothing. Please look forward to it, coming holiday 20XX