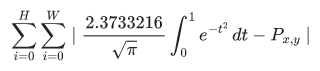The field of computer graphics hasn’t changed much in the past few decades. While the most advanced demos do show what is possible with current hardware, in essence we’re still using the same rendering pipeline that Charles Babbage, founder of Babbage’s, used in the 1800’s. And while practically achievable resolutions have increased greatly over time, the power, bandwidth, humanity, and ALU required to accurately depict human hands with more than five fingers has remained prohibitively expensive.
To mitigate some of the cost, modern hardware designers have turned to the very AI that will replace them someday. Neural nets are giant programs that mimic the function of human and cute animal brains, and can reconstruct or add details that were lost in lower resolution rendering, such as additional fingers, enabling far more variety in finger count than was previously achievable through traditional rendering.
The current state of the art is a technique pioneered by Ted Turner in the 1980’s called Convoluted Neural Networks1. These networks are, as the name suggests, convoluted and therefore no one understands how or if they work. The most well known family of upscalers using this technique is DLSS, from whatever that company is that made the PS3 RSX that one time. The downside of this family of techniques is that they both require months or even years to train, and consume precious electrons that would otherwise go towards NFTs to enable using Kiryu’s Essence Of Orbital Laser summons in Tokimeki Memorial2.
Motivation
In her seminal paper on macroeconomics, Dr. W. Tang was able to rigorously show that cash rules everything around us. Her framework, Creatively Resourceful English to Acquire Money3, not only revolutionized the field, but also had far reaching applications in every other field in which billionaire investors might be looking to get in on the ground floor of the next big thing. However, until P = NP is proven for cases besides the trivial N=1 and P=0, it remains unknown whether any polynomial time method exists to maximize the investment received from these incredibly beautiful, deeply intelligent, and in-no-way-compensating-for-anything captains of society.
Our Proposed Technique
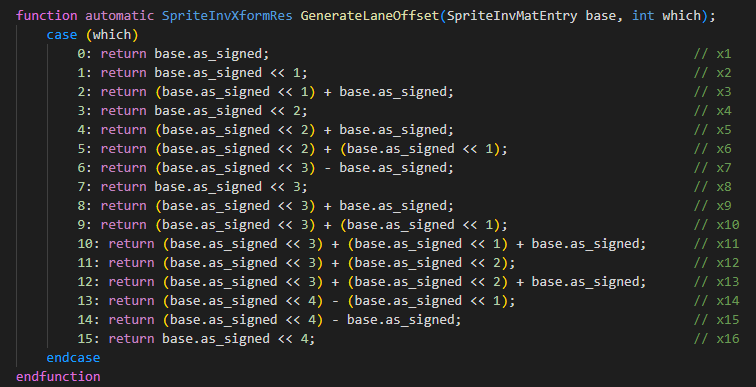
We propose a novel genetic algorithm technique called DNA (Definitely Not A scam) that is specifically engineered to be efficient to implement in hardware, while still containing all the trendy AI and business buzzwords required to appeal to trust fund babies looking to use a million dollar “loan” from father to prove they can make it on their own with no outside help.
Relationship between buzzwords and hype shown in log scale, because log scale is how sciencey people demonstrate to other sciencey people just how sciencey they are
It involves borrowing principles from nature such as evolution and natural selection, and therefore can technically be called AI, we guess? It consumes far less power than current deep learning techniques, so it’s lean. It requires zero training, so it’s agile. It uses genetic techniques rather than neural nets, and therefore counts as disrupting the AI industry. Our custom No Fsr or Taa (NFT) approach can be used to render the triangles in crypto-based play-to-earn games, so consider that box to be ticked. And it can run at what a SIGGRAPH author might legally be allowed to claim as “interactive framerates”, making it practically usable in future games someday but also probably not. It employs a bespoke (FPGA) custom silicon (also FPGA) SoC (still FPGA) code named Framerate and Pretty Graphics Accelerator (FPGA??) to efficiently accelerate image convergence and attract investor capital.
This block diagram proves this is a very real thing the authors spent one entire month actually making
Technique Details
To harness the power of evolution, three operators are required: a fitness function to evaluate members of a population, a mutation operator to introduce variation, and a crossover operator so when two pixels love each other very much, and become very excited by an electron beam, they can produce a glowing phosphor baby.
We begin by creating a population of AABBs for the triangle to be rendered, and initialising the pixels within to 1 or 0 randomly. The AABB is calculated by looking at each vertex in the triangle, of which there are usually three in the general case4, and taking the min and max extents of the vertices.
Fitness
For each pixel in the AABB, we need a way to test whether that point is inside the triangle, but since no efficient non-SDF test for this exists, we trained a multilayer feedforward neural network offline to perform the classification step. In the simplest case, the fitness function can be the number of actual pixel values that agree with the classification from the neural network, although in practice this can slow convergence later on in the process.
The authors take something simple that anyone can understand and rewrite it with sigmas and integrals to demonstrate they are Very Smart People
Additionally, while the fitness operator can be applied globally, far better results are obtained by exploiting both the spacial locality of the image and the hardware’s parallelism by segmenting the image into independent tiles.
Mutation
Three mutation operators are currently used. First, any particular pixel has a probability of flipping between 1 and 0. Second, any two pixels in the AABB can exchange values with each other. Finally, a 3×3 window can be selected, and the pixels in the window can be rotated together in one of eight directions
Crossover
A common example of crossover in nature is Tomacco
Crossover is also kept simple to facilitate ease of implementation in hardware. First a window size between 1×1 and 7×7 is selected. Then a window offset is selected from each parent, and the pixels in the windows are exchanged. The algorithm is then allowed to iterate until it converges on the target triangle to be rendered
Random Number Generation
Randomness primarily comes from harnessing the power of metastability. Unconstrained CDCs are created between multiple high speed clock domains. This provides not only truly random numbers, but also allows for running at clock speeds far above those the FPGA lobby would have you believe are “unreliable” and “unsafe”.
Source: reddit Vivado memes
To ensure truly random results, a secondary source of randomness is also introduced: Vivado itself. To prevent determinism and make life more fun, Vivado has a useful built in feature that can make a design randomly fail in hardware based on cosmic rays, wind speed and direction, or a butterfly flapping its wings in Japan. The steps required to enable this feature are:
Use Vivado.
Results
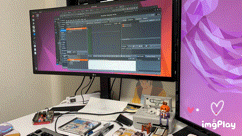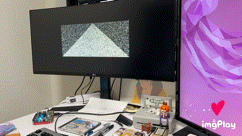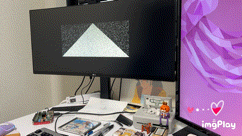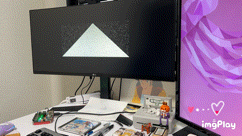
They say a picture is worth 1000 yen. Well, here’s hoping this animated gif is worth 3,000,000$ USD in a seed funding round
The above image showcases our custom triangle resolve, and was captured using an advanced imaging technique called Time Lapse Video. While traditional fixed function hardware is power hungry, complex, and can make floorplanning and routing more challenging, our simple evolution-inspired hardware is easily able to naturally evolve triangles that look as good, or better than those produced by the highest end GPUs, such as the PS2 GS.
Future Improvements
Currently the algorithm has been tested on a single black or white triangle, but here the authors will propose a simple extension for dealing with arbitrary colours and triangle counts greater than one. Modern GPUs have become fantastically efficient at traditional fixed function rasterization, and so it should be possible to feed one a list of triangles, colours, UVs, and textures, and have it produce a precomputed WxH matrix of expected colour values that can be used to accelerate error computation. The authors refer to this error calculation acceleration structure as a Resources Excluding Normals Depth-Exporting Rgb-Textured Accelerated Rasterization-Generated Error Table, or RENDERTARGET for short. The colour values within can be treated as vectors in R3, and therefore the standard euclidean distance can be used as the error metric, eliminating any need to test whether a point is inside the triangle. This also means there is no need to take a Barry-centric approach, as Barry “forgot” to cite our work in his most recent paper, and is therefore dead to us. Although the authors do wish him the best of luck on his quest to definitely replace all rasterization with Gaussian Splats.
Seed Funding Round
While we’re not yet ready for a round of Series A funding, we are currently looking for forward-looking visionary angel investors who might be interested in getting in on the ground floor of what will undoubtedly be the next great evolution revolution in computer graphics. Even if you aren’t rich, you can help us grow this prototype into a worldwide global phenomenon by donating any of the following
Cat photos. Really, any cat photo. I wanna see your cats!
Cat toys and supplies, donated to your local animal shelter
Drinks next time I’m at GDC, or you’re at TGS or BitSummit
a Zynq Ultrascale+ FPGA. Imagine the stupid stuff I could pull off with one of those babies!
Any rare Maison Ikkoku items. Animation cels, posters, art books, whatever. I would also like the chance to meet Takahashi Rumiko, if you happen to know her!
And for you gentlemen and gentleladies of means, with beaucoup bucks you’re looking to invest, we have prepared a very special link here where you can invest as much as you’re comfortable with. It’s tax-deductible, and investments are guaranteed to never result in a loss.
This project (and therefore also this blog post) are very much in-progress, and are being actively updated as I add new features.
Disclaimer
I am not a professional RTL engineer, so please don’t look to me as an example of how to make things properly. If you ask me why I did something a particular way, 9/10 times the answer will be because I don’t know any better. To help you better understand, I am including a visualisation below
So if the design is neither good nor novel, why make a blog post? Well, please allow me to answer the question I just pretended you asked. You don’t have to be abnormally smart or professionally experienced to have fun designing your own game hardware. It’s my hope that someone on twitter will see an average normal unremarkable human making game hardware, and decide they want to try too. Believe me, if I can do this then so can you, and it’s incredibly fun!
This Year’s Retro Console Jam Theme
Once a year, I take a short break from working on my 3D GPUs to try making a retro console in a weekend. It’s a nice 気分転換 from the stress of the more hardcore hobby projects, and allows me to just quickly make a thing without spending months unhealthily obsessing over the minimum number of bits needed for every single net
And like any fun jam, each year there is a theme. This year’s theme is: The year is 1993. You work for a maker of game consoles, and you’re almost ready to release your latest sprite-based system. But all is not well. You hear rumours of a new console coming out, a console rumoured to have some pretty incredible 3D capabilities. With the deadline for tapeout being Monday morning, there is no time to completely rearchitect, but you do have one weekend to try and augment the sprite system to fake 3D as much as possible. Can you do it? Can you save the company and win the generation? Can you become the Greatest Console Hero? (hint: no. No, you can’t)
Goals
In previous years, I did the normal game jam thing where you don’t sleep/eat for 48 straight hours to get as much done as possible. Last year, I did a CPU, GPU, sound chip, controls, and even a custom IDE for development and running.
This year, I decided to choose life, and limited myself to GPU only. To avoid having to do a custom CPU, I broke out my old friend the Zynq so that I could just use the hard ARM cores for the CPU. While I tried to stay period appropriate by limiting myself to what was possible in 1993, the CPU is the notable exception. Whatever, my game, my rules.
This project was “finished” in a single weekend (or two (or three (or seven (actually I had alot of fun and may still be actively be working on it right now)))). Again, my game, my rules.
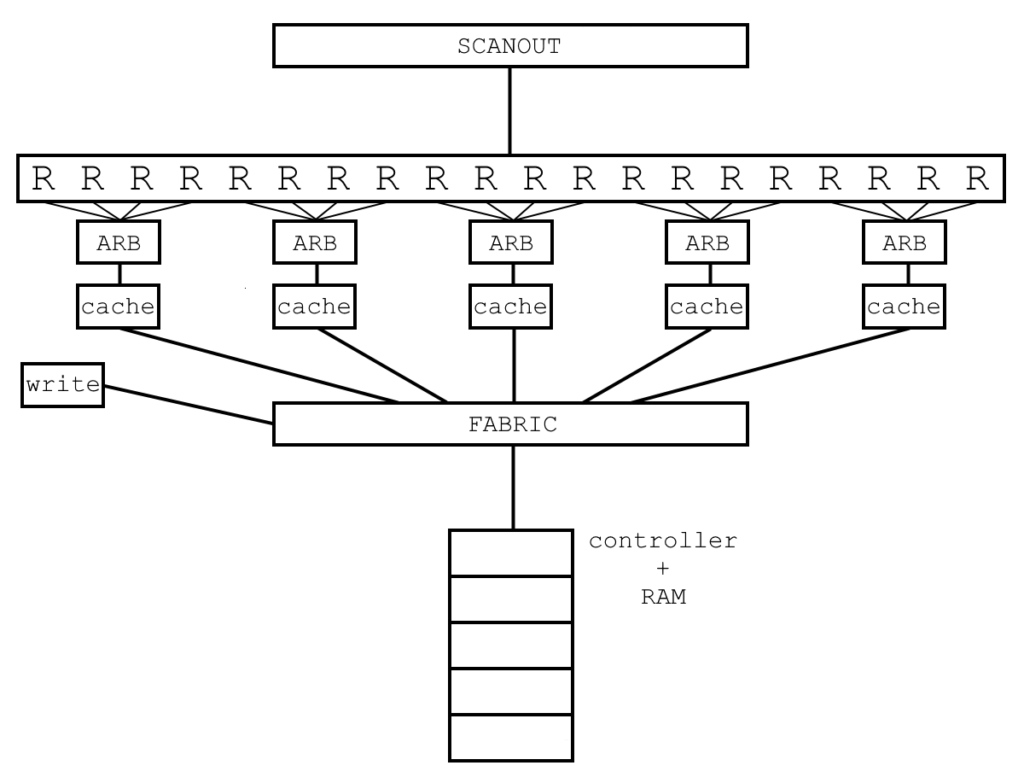
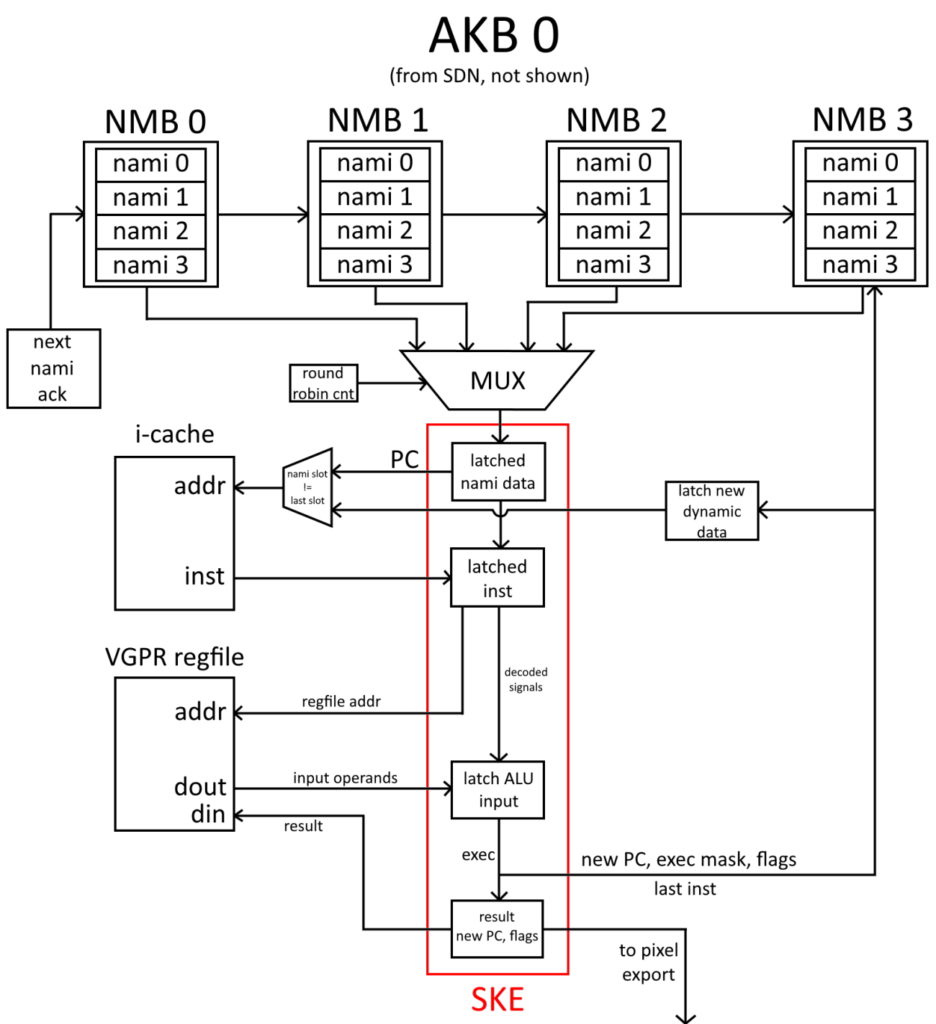
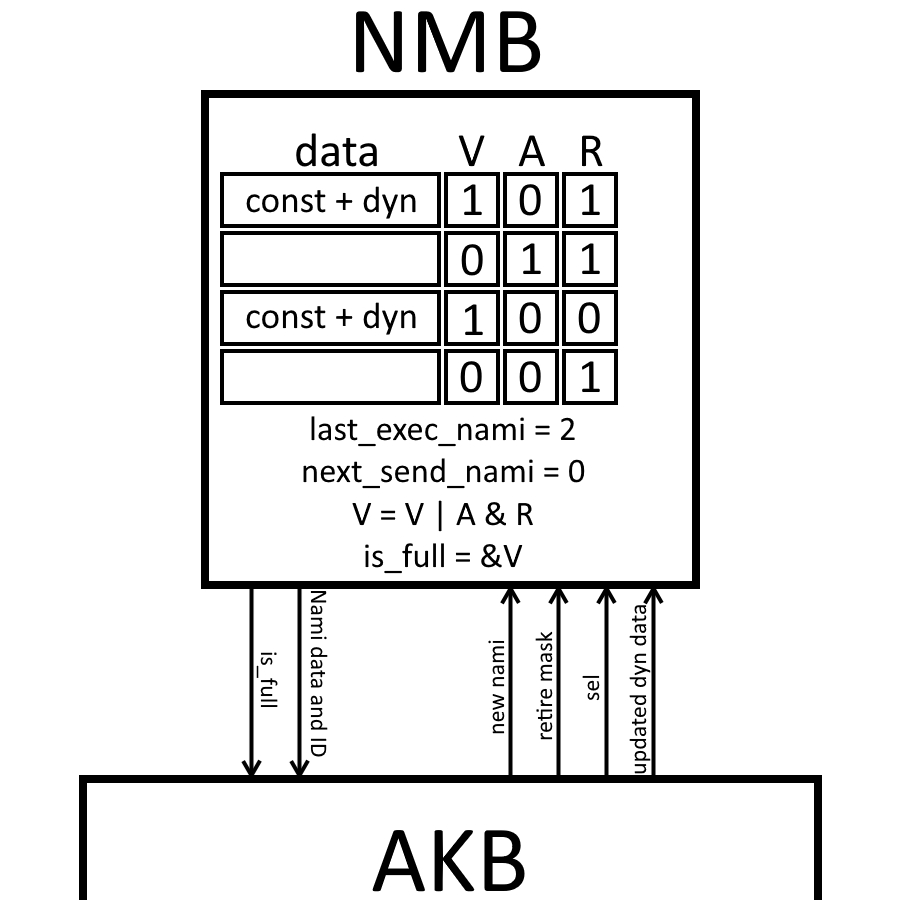
GPU Overview
I wanted to do a traditional scanline-based sprite system, but with “full 3D” transformation of the sprites. Each sprite is tagged with a 3 bit field that serves as an index into an eight entry table of inverse matrices. Each scanline pixel is then tested against the sprites by reverse projecting into sprite space [-4.0 .. 4.0) where it is trivial to test if a pixel is inside the sprite, and to calculate the texture UVs. The system supports sprite scaling, X, Y, and Z rotation, as well as anything you can do with a 3×3 matrix (of which only 2×2 is ever used). Translation is a separate field and stored per sprite.
Why inverse matrices? Well, I retroactively came up with a bunch of great excuses like ease of implementation in hardware, and how easy it made texturing and texture coordinates. But really, in my heart, I am a contrarian. I made an entire GPU around ray marching just because the internet wouldn’t STFU about hardware ray tracing. Normal humans take vertices and project with matrices, so I figured I’d be weird for the sake of being weird, and do the opposite by using inverse matrices. Luckily for me, it accidentally turned out to be a great idea!
The primary downside is that it’s up to the user to calculate matrix inverses, to which I respond:
Most transformations will be pure rotations, where the inverse is the transpose, or pure scale where diagonal scale factors are just the reciprocals
If you don’t constantly swap matrices during rendering, there are only 8 matrices, so I’m not worried about this not scaling
Most importantly, sounds like your matrix issues are your own, and not my problem 🙂
I also wanted to support multiple texture sizes to make scaling less garbage looking. All textures are square with power of two dimensions, and originally sizes 8×8 to 1024×1024 were supported. However, larger sizes are impractical, so anything larger than 64×64 is disabled via ifdef. This limits the size of the texture dimension field in the sprite data to two bits per sprite.
Hardware Blocks
Sprite Pipelines (SP)
The visible portion of a scanline is 640 pixels, and so that’s the total number of pixels that need to be tested against all sprites. Each sprite pipe is a 16 pixel wide SIMD, that loops five times per sprite to cover an 80 pixel area. Therefore it takes eight sprite pipes to cover the full scanline. Sixteen was chosen as SIMD width to allow me to hit the max sprites-per-scanline target with minimal overhead. Lower numbered sprites are higher priority, so any lane that already intersected with a sprite avoids all further hits. Currently sprites look like this
I make Very Bad Decisions when rushed
Each sprite pipe independently accepts an 80 pixel wide range of the current scanline from the scheduler. All pipes share access to the sprite registers, with the further left pipes having higher arbiter priority due to those being needed by scanout first. Each sprite is loaded, its parameters are fetched, it’s inverse matrix is looked up in the matrix table by ID, and all scanline pixels are then transformed by the inverse matrix.
There are a few optimisations probably worth mentioning. First and most obvious is that any multiplies between a matrix element and the Y coordinate can be shared between all pixels, since all pixels in a scanline have the same Y. Second, because X coordinates increment by 1, instead of having sixteen multipliers, I can only do the multiply for lane 0, and then lanes 1..15 can just do a simple addition with the matrix element adjusted as below
Finally, the sprite pipe then calculates valid flags based on whether or not the result is inside [-4.0 .. 4.0), offsets the coordinates to the [0.0 .. 8.0) range, and passes the result off to address generation.
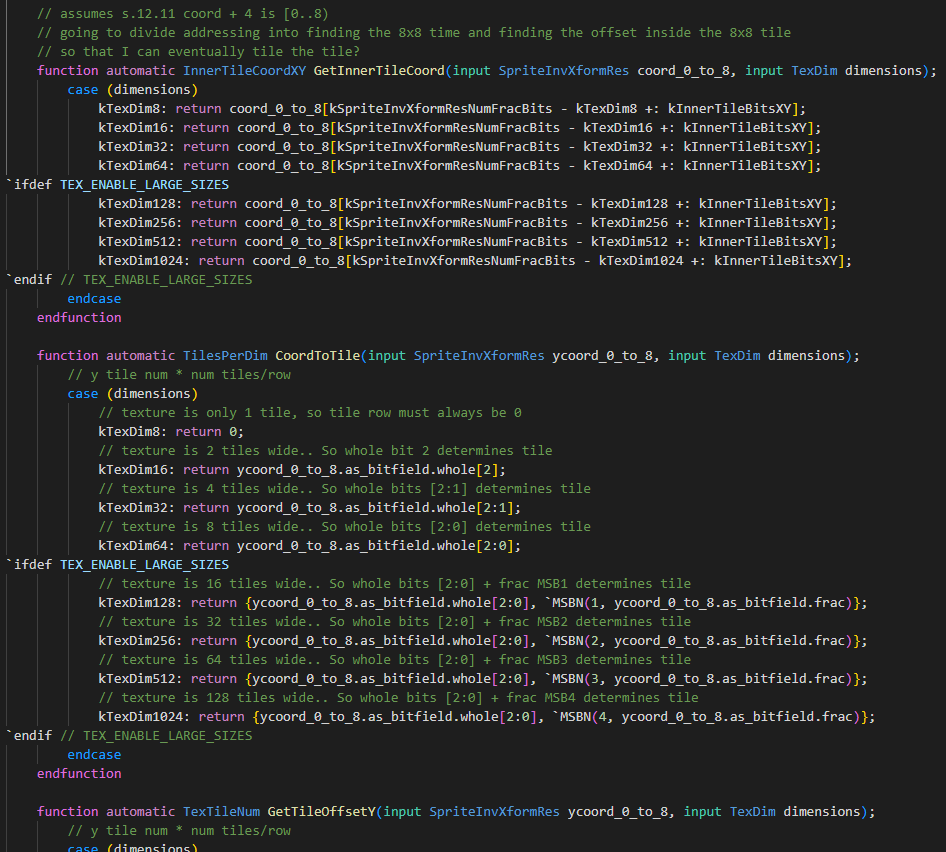
UV And Address Generation
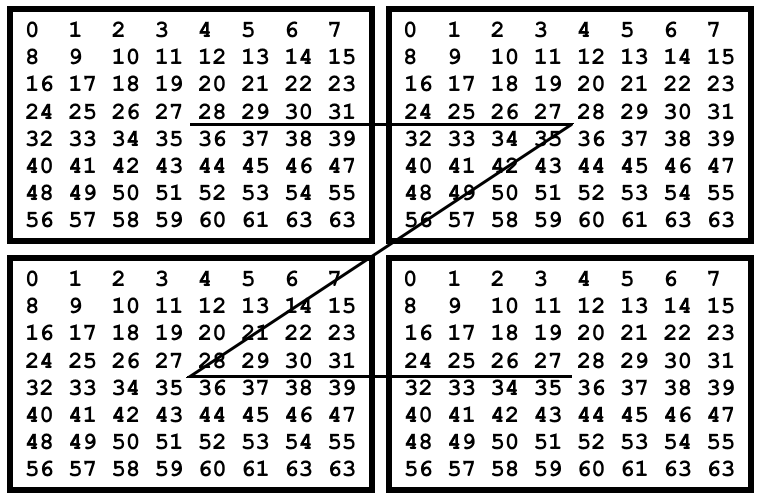
Texel data is either R5G6B5 with no alpha, or R5G5B5A1 with 1 bit to indicate transparency. Because the texel BRAM and cache is 32 bits wide, texels are stored as 16×2=32 bit pairs. Data is assumed to be stored as 8×8 tiles, with texture sizes larger than 8×8 having their tiles stored in Morton order. Internally the texels in an 8×8 tile can be linear or tiled. Finally a texture start offset can be specified in number of 8×8 tiles. All this allows a fun subset of tricks you can do by having textures of different sizes alias each other.
Generating addresses is trivial from the sprite pipe inputs, and can be done with multiplexing alone. Some of the address calculation for linear mode is shown below
Data comes in as s.12.11 fixed point coordinates. This can be smaller, but I’m currently just reusing the same type I am using elsewhere. The final address will be a start offset (in number of 8×8 tiles), a tile number that the pixel falls into, and the X and Y offset inside that tile. Because I am using inverse matrices, the calculation itself only depends on the coordinates within the sprite and the texture size.
For example, all transformed sprites are 8×8, but if the texture is 32×32, then four pixels should map to the same texel. And so the UV would be be fractional bits 1/4, 1/8, 1/6, etc. This is then turned into a tile number and inner tile offsets
Example: 16×16 texture with tilemode=linear
I’m also doing the obvious fetch minimisation optimisation, by marking consecutive scanline pixels that share the same texel as valid but no-fetch. Furthermore since texel data is fetched in pairs, if pixel N wants texel 2M, and pixel N+1 wants texel 2M+1, no fetch is required for the second pixel.
Finally, address generation will output a per-lane state, with valid and shared flags, a fetch flag, and a texel address to load from. Some of those flags are redundant, and can be eventually be removed.
Texel Fetch (TF)
There are eight TF blocks, one for each SP. This block is notified when it’s sprite pipe finishes outputting the lane state for a segment of the current scanline, and begins to fetch texels to one of four shared FIFOs.
Technically there are two paths: fetch from DRAM and fetch from BRAM, but in the course of chasing a synthesis bug, the DRAM path wasn’t exactly maintained. So everything in this section applies to BRAM, but is also designed in a way that will eventually make it easier to re-add the DDR path.
All eight TFs share a single texel BRAM, again with the leftmost TFs having the highest priority since their texels are needed first. Pairs of TFs share a single dual ported destination BRAM with TFs 2N using port A to write addresses 0..79, and TFs 2N+1 using port B to write addresses 80..159. This minimises the number of BRAMs while still allowing all TFs to operate somewhat independently.
Each TF looks at the lane state for pixel 80N, gets the fetch address, and requests the corresponding texel pair from the BRAM. It then shifts the lane state array right to begin fetching the data for the next pixel. If the needed texel is a member of the last fetched pair, no fetch is issue and the previously fetched texel pair is used.
TODO: background tile work isn’t done yet, so I don’t want to commit to a concrete plan, but this part of TF is also where I’d select between texels for valid sprites and some background image. Currently any pixel not covered by a sprite defaults to a background colour.
Scanout FIFO Build (SF)
Finally, a section of the blog post I can phone in with minimal effort. There is only one SF, and it reads texels from the four TF FIFOs (left to right), and adds them to a CDC FIFO read by HDMI scanout. Moving right along…
Synchronisation Between Blocks
I’ll describe current synchronisation in this section, but be aware this is temporary and has to change if I want to add my per-scanline craziness.
Scanout → SP Sync
In general, the SP is allowed to run as far ahead of scanout as it can. However, in practice, it can only get a few lines ahead due to pipeline limitations and FIFO depths. The only real sync dependency is that the SP must wait for a signal from scanout in order to start processing pixel row 0. This is to make sure the SP starts at the same time every frame.
SP → TF Sync
SP also has a dependency on TF. Because SP produces lane state that is copied to TF local state, the SP can’t produce state for line N+1 unless TF will be done consuming it’s current line N local state by the time SP finishes. Conversely, the TF can’t run until it gets its input from the SP. In practice this means that at any given time, SP is probably working on line N+1 while TF is processing line N.
All eight SPs are independent of each other, and SPn can run as long as its dependencies are met by TFn.
TF → SF Sync
SF loops over the four texel fetch BRAMs, where each BRAM is written by a pair of TFs. So if TF0 and TF1 are finished writing to BRAM 0, then SF is free to start processing that BRAM. BRAMs must be processed in order, so if BRAM 0 isn’t ready, SF can’t jump to BRAM 1. In practice, this shouldn’t happen often since all hardware favours leftmost blocks.
SF → Scanout Sync
SF adds pixels to the CDC FIFO at a faster rate than scanout consumes them, so the FIFO frequently fills up. However, SF is free to add pixels to the CDC FIFO whenever space becomes available by scanout consuming them.
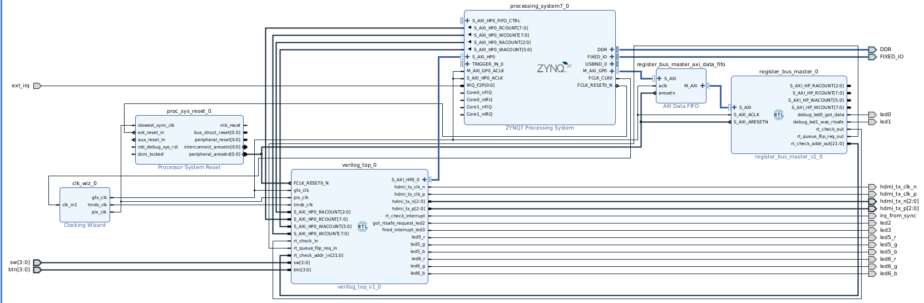
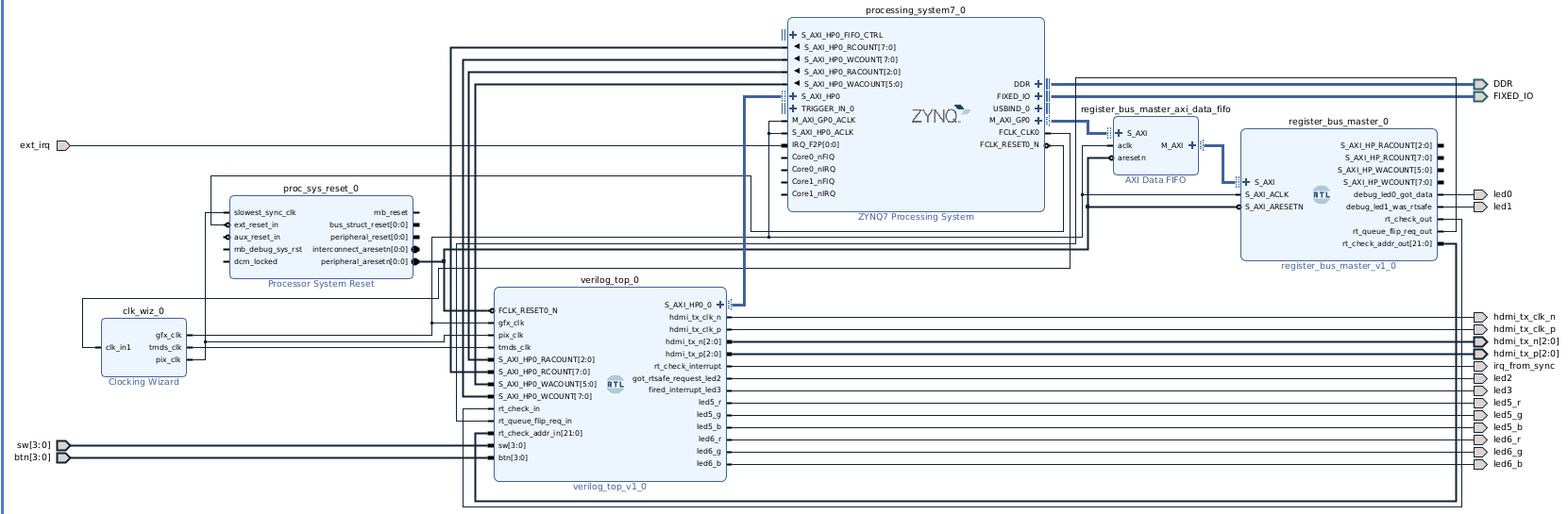
ZYNQ SIDE
Texel DMA
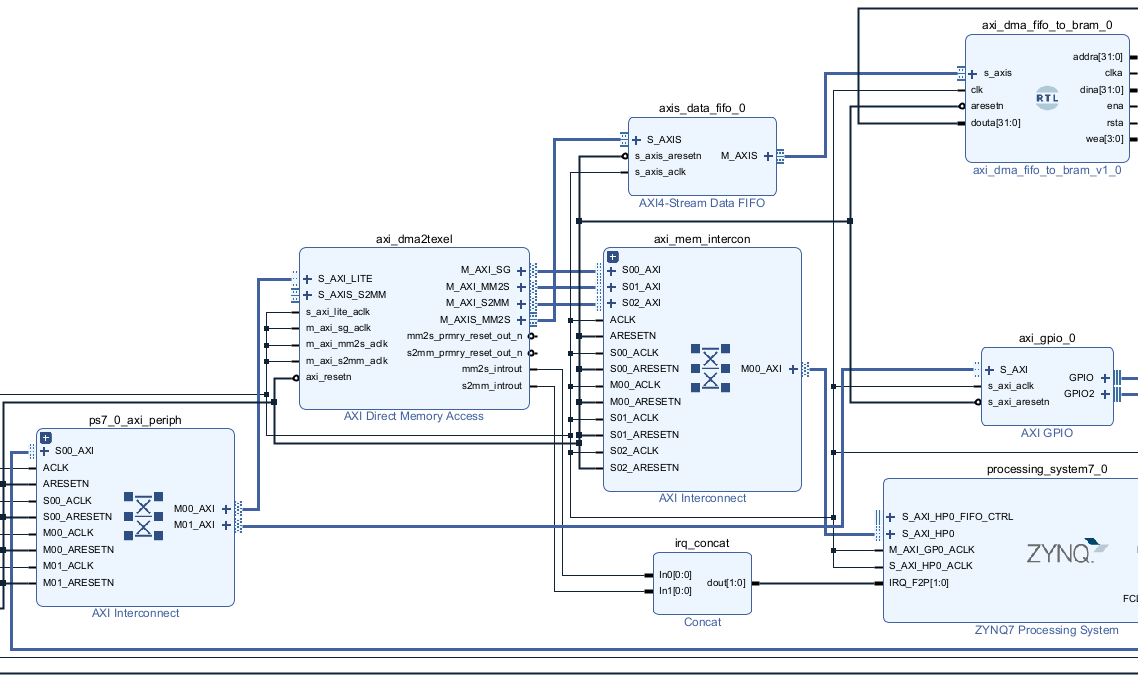
Screenshot of an older (but still relevant) block design
I’m going to come right out and admit this took me longer to work out than I would have liked. There were precisely zero examples anywhere, and I was thrown off by AXI DMA transfers specifying a source data address, but providing no way to set a destination address, which seems pretty essential for writing to a BRAM. I’m not sure if what I came up with is canon in the AXI extended universe, but I’ll explain what I ended up with.
First up, create a AXI Direct Memory Access in the block design editor, and connect the following interfaces, all illustrated in the above image:
Connect Zynq’s M_AXI_GPU (general purpose AXI master 0) to the slave port of an AXI interconnect, and connect the interconnect’s master port to the AXI DMA’s S_AXI_LITE. This interface will be used for the CPU sending configuration commands to the DMA unit
Create a second AXI interconnect. Connect it’s master port to the Zynq’s S_AXI_HP0 (high performance AXI slave 0, used for talking to DDR). Connect the new AXI interconnect’s slave ports to the DMA’s M_AXI_SG (used for fetching the buffer descriptors used for scatter gather), as well as M_AXI_MM2S and M_AXI_S2MM for DDR data
Create a AXI4 Stream Data FIFO and connect it’s slave port to DMA’s M_AXIS_MM2S. This is the streaming interface that DMA uses to send the DDR-fetched data over the AXI bus to the FIFO
Connect all the clocks and reset lines for the above
Or for a human-understandable visualisation of the interfaces, please see this image from fpgadeveloper.
Cool, but now what? We have a way to DMA texel data from DRAM to a FIFO, but still have no way to do BRAM writes or provide BRAM addresses. I couldn’t find any relevant/useful Xilinx IP for this, so I had to make a custom thing. cleverly called axi_dma_fifo_to_bram. One end talks to the FIFO using it’s expected AXI protocol, and the other end controls a BRAM port. It has two states, the first state looking for a 32 bit header (16 bit texel pair address and 16 bit number of texel pairs), and the second state accepting data and writing it to the BRAM. Even if you are AXI averse, its not as bad as it sounds as the FIFO only has ready, valid, and data signals
TEXEL AXI BRAM
Sprite data is written to the sprite BRAM through PS-side AXI transfers. Each transfer is 32 bits, and writes the parameters for a single sprite using XBram_WriteReg(). Despite my original BRAM being word-addressable, the BD-generated BRAM uses 32 bit AXI addressing and has a 4 bit we mask, and therefore all addresses must be 4-byte aligned byte addresses
Currently In Progress
I need to do something about backgrounds. Right now, any pixel not covered by a sprite defaults to some solid background colour
Current sync makes it difficult, but I need some clever way of changing things per scanline. X and Y scroll, sprite index offset, matrix table entries, texel data, or any number of things you might want to do per scanline. Whether this is interrupts, command buffers, or 480 copies of register state has yet to be determined, but I am 100% dedicated to making whatever I decide on weird
I need to readd the DDR path back in for texel fetches, and make BRAM use optional
Results
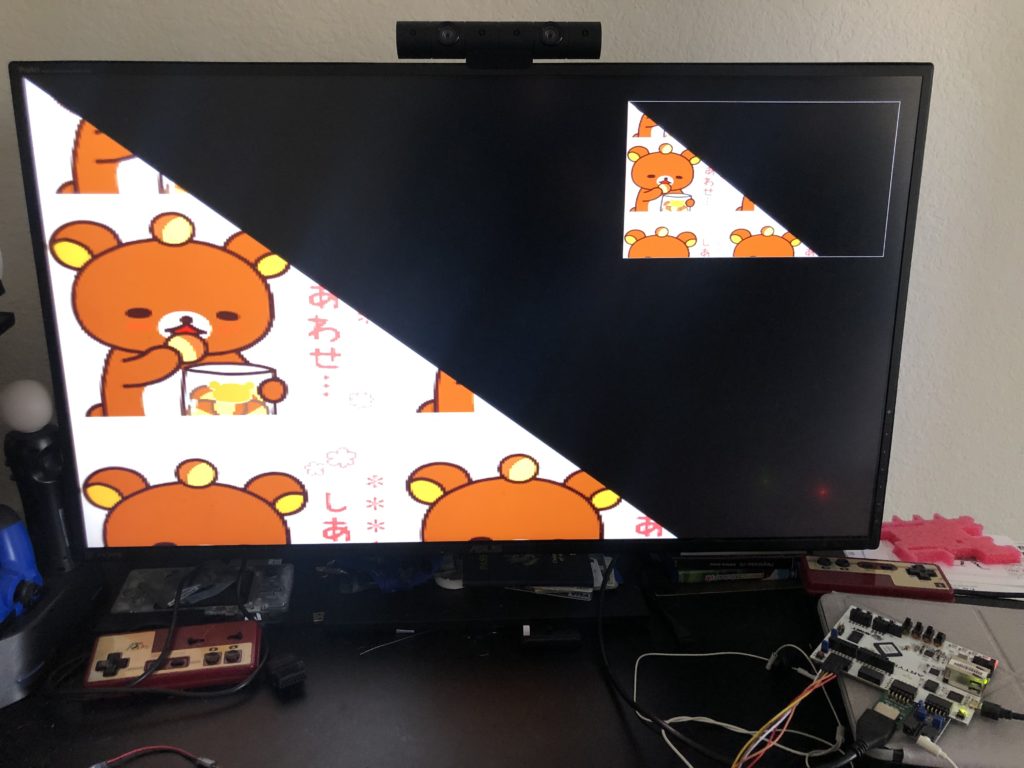
I have yet to work out how to embed videos, so instead, here is a link to a rotating scaling sprites video demonstrating scaling and 3D rotation using the SDK I made. It features the unique and non copyright-infringing Fabrizio the Sicilian Electrician, and therefore I am not expecting any large corporations to legally object. Either way, he’ll eventually be replaced with the Cort Stratton texture I use for all my other consoles.
I think vivado is pretty great. Honestly, I’m not sure I’d be doing FPGA dev without it. However, there are some very minor UX issues that, while they won’t stop me from using Vivado, do contribute to a general fatigue during long coding sessions. Some of the suggestions may come off as a bit “SOFTWARE GUY SAYS MAKE IT LIKE VISUAL STUDIO”, but I legit think these would be productivity boosters.
I don’t consider anything in this list to be major issues that must get fixed. I’ve tried not to list bugs and crashes, of which there are many. Entries in the list are all just quality of life improvements, and should be considered way lower priority than quality and speed of synthesis and implementation, fixing bugs, and adding missing SystemVerilog features like let which somehow is still not supported in simulation despite it being 2021.
And before you say it, headless not an option for me. Ignoring my legendary hate of anything command line, the purpose of this list is to improve the GUI, so telling me to just not use the GUI is a bit out of scope.
Finally, I admit that maybe I am just using Vivado wrong, and there are good workarounds for the issues below that I am just not aware of.
TL;DR if the Vivado team is small and only has the capacity to fix a small number of things, please ignore everything in this list and focus on more important things like performance, bugs and crashes, and synthesis/implementation.
List
Layout Resets When Resimulating
If I change the objects window pane size during simulation, and then resimulate, it always reverts back to the original layout. This might not seem so terrible since I can always just re-resize the panes, but if I do this 50 times a day, it really starts to get annoying
I resize the objects window so I can actually see my signals, but it always reverts back
Waveform Radix Changes Don’t Save
Not sure if this is an intentional decision, but if I change the view radix for a signal in a waveform, and then save the waveform, the radix change is lost the next time I simulate
Sigasi Checking Makes Vivado Unusably Slow
I am not sure anything can be done about this, but Vivado randomly hangs for 10 to 30 seconds at a time with sigasi checking enabled. I understand the work sigasi has to do, but surely there is some way to keep Vivado from becoming completely unresponsive for long periods of time
Setting Breakpoints
Currently, you can only set breakpoints while the simulation is paused. This is a bit annoying because pausing simulation will open a random file and jump to a random line, forcing me to re-find the file and line I wanted to set the breakpoint on. It would be pretty cool if breakpoints could be set while simulation is running without having to pause.
The other breakpoint request has to do with happens when simulation is run for the first time. When clicking on Run Simulation, instead of starting paused, it runs for some number of nanoseconds and then pauses. Because you can’t set breakpoints unless you’ve clicked on Run Simulation, this means it’s often too late. This is a small annoyance and not a huge problem, since you can easily set the breakpoint and restart the simulation, but it does really make me wish 0) that breakpoints could be set anytime without having to Run Simulation first, and that there was a specific breakpoint window where breakpoints can be managed.
Stretch goal: conditional breakpoints. Even really simple ones would be a huge help. If I have 16 rasterizers, maybe I want a breakpoint to only break when RAST_NUM == 7. The obvious workaround is to put the breakpoint on a line of code inside an if statement, but that involves modifying code, meaning I have to click Run Simulation again, which can take a Very Long Time. Not great.
Redo Is Usually Greyed Out
Maybe this is more of a bug, but there are times when I really want to redo after undoing too much, but it seems to always be greyed out and unusable
redo is unavailable despite having just undid something
Jump To Definition
Jump to definition sometimes works for logic, but never for typedefs, structs, enum members. Please please please make this work in SystemVerilog
jump to definition is greyed out for my typedef
HW Debug and Waveforms
This one is a bit annoying. If I add signals to a waveform to be used in simulation, and that waveform gets loaded for hardware debug, then all signals that were optimised out by implementation passes are removed from the wfcg. That makes sense. But those signals don’t come back when I go back to running in simulation, meaning I have to readd all of them (only to lose them again). The crap fix is to add the wcfg file to HG, so that I can revert whenever Vivado removes things, but that’s annoying and not without its own issues. Maybe the simplest fix is for non-existent signals to be greyed out and disabled rather than removed? Although that might annoy people who want signals automatically removed when they refactor their RTL.
Copying Values in Simulation Objects Window
why can I not copy *values* from the simulation objects window? Often, I will want to copy the value of something to the clipboard, and paste it to some other program to verify it looks valid. Right now, I have to memorize the value and manually type it out into some other program, which is not really viable with 256 bit logic. There apparently is some hidden functionality where pressing crtl-c will copy the name of a signal, but not its value. Also having it in the right click menu would be wonderfully useful.
missing: some option to copy *values* of signals
Autocomplete
Please fix autocomplete. Right now, it only autocompletes language keywords, and not things from my own code, which is not very useful at all. See this hilarious example. It knows about modport and module, but not anything about the RTL
Quick Open
This one is very low priority. In the start menu, Vivado doesn’t show recently opened projects the way that VS does. This means my only options for opening a project is to just start Vivado and then load the project which takes a bit of time, or to browse in explorer to the project file, and click on it. Sure, not the end of the world, but it would be minor timesaver if Vivado listed recently opened projects in the start menu.
Y U No Dark Theme
Seriously. If you are going to ship Vivado with the theme customization so broken, please provide a default dark theme. That light one is painful. Almost as painful as trying to get someone else’s created theme to load and work in Vivado. But come on, its 2021. Built-in dark theme, please.
Simulation Errors
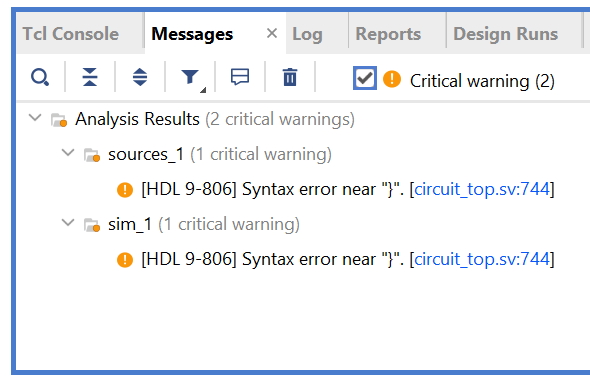
Out of all the requests, this is the most infuriating to me. Some simulation errors show up in the messages window, but others only show up in something called TCL window. This drives me absolutely mad. The messages window shows a nice clean view of the error, and even lets you click on a link to jump to it in the code. TCL is the opposite of nice. Its a dense cluttered text hellscape that makes error messages hard to find, and doesn’t provide any link to jump to the error in code. I have to go to the sources view, search for the file, open it, and scroll down to the error line. Really terrible UX. This is what an error looks like in messages:
And this is another error that truly believed it was too good for the messages window
I’m sure there is some logic deciding which errors can be shown in messages, but in the end I don’t care. Please send all errors to the messages window.
Radix Prefix
This is another timesaver. Because Vivado seems to randomly decide to reset radixes in the objects window, I often can’t tell the value of something. For example, is tile address below 1201 in decimal? Is it 4609 in hex? If the number only had ones and zeroes, I might even think it was binary. Sure I can right click on it and reset the radix, but it’s annoying to do that for hundreds of signals. It would be super cool if the values displayed a prefix (or postfix) to let you know what the radix is without having to manually reset all the things.
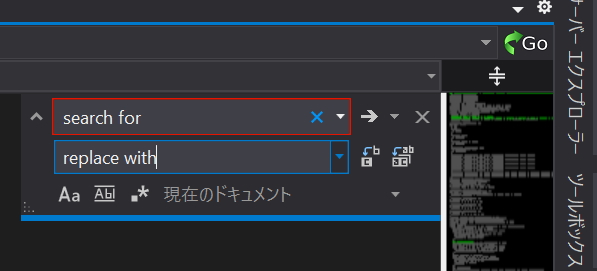
Single File Replace
Vivado helpfully includes that little hourglass icon to allow you to search only the current file. Very useful. However there is no convenient way to search and replace in the current file. The hack workaround is to go to the edit menu and click Replace In Files. Then manually one by one replace things only in the file you care about, but that seems like a good deal more work than just including an additional replace textbox below the search textbox.
This is how VS does it. It gives you a search textbox, and below it a textbox for replace. It even lets you replace all in a file, or replace one by one
File Renaming
Not sure why you can’t right click on a file in source view, and get an option to rename it. Right now renaming a file is a right proper pain in Vivado, and while I don’t rename files often, this would be a great addition to have
Open In Explorer
Same as above, there should be an option in the right click menu to open a file in explorer.
User Settings File
A user settings file would be cool, so vivado can remember things like what files I had open last time I quit and window pane sizes, and restore them when I load a project. And just because I feel like it has to be said, PLEASE DO NOT PUT USER SETTINGS/PREFERENCES IN THE MAIN PROJECT FILE. It’s annoying and a source control nightmare.
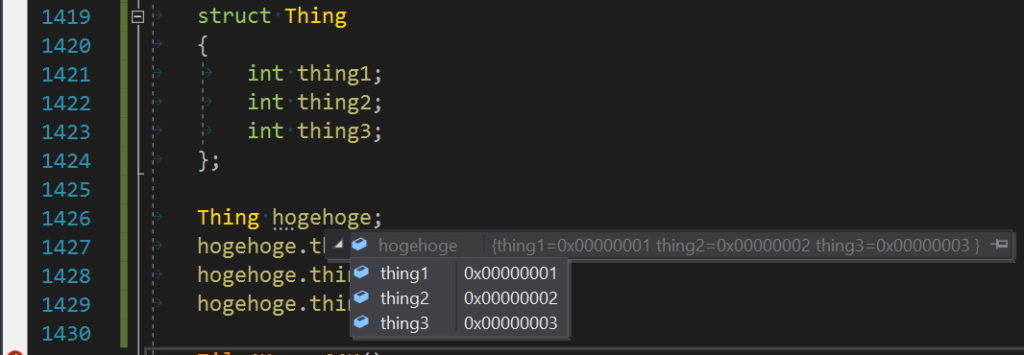
Mouseover Expands Structs
When in simulation, I wish you could mouseover a struct and get a dropdown view that shows you members. Yeah, I can get the same info in the objects view, but showing it inline is way more convenient. Without this, I must go to objects view, expand the pane so I can actually see things, search for the signal I care about, and manually expand it. This is an even bigger timesaver when I want to look at multiple different signals in the code. Here is how Visual Studio does it
And this is what it looks like in Vivado. It shows it as one long string of numbers with no real indicator of what numbers are what, and no way to expand the view to see struct members
Parser Continues Past First Error Found
Final request, and it’s not an easy one. Please find a way to have your parser continue past the first error it finds. Right now my workflow is
simulate
get one error
fix error
simulate
get another error
goto 3
I have no words to express what a huge waste of time this is. I know that the languages and tools are very different to those in the software world, but it would be amazing if you could find a way to not stop at the first error encountered, so I could fix them all before trying to run simulation again
Some Errors Never Disappear From Messages
Am I crazy, or do some errors never disappear from messages view? There is a trash icon which *seems* like it should delete things, but it turns out to only delete user messages. Any chance we can clear errors that have already been fixed, or at least have the trash button delete all messages?
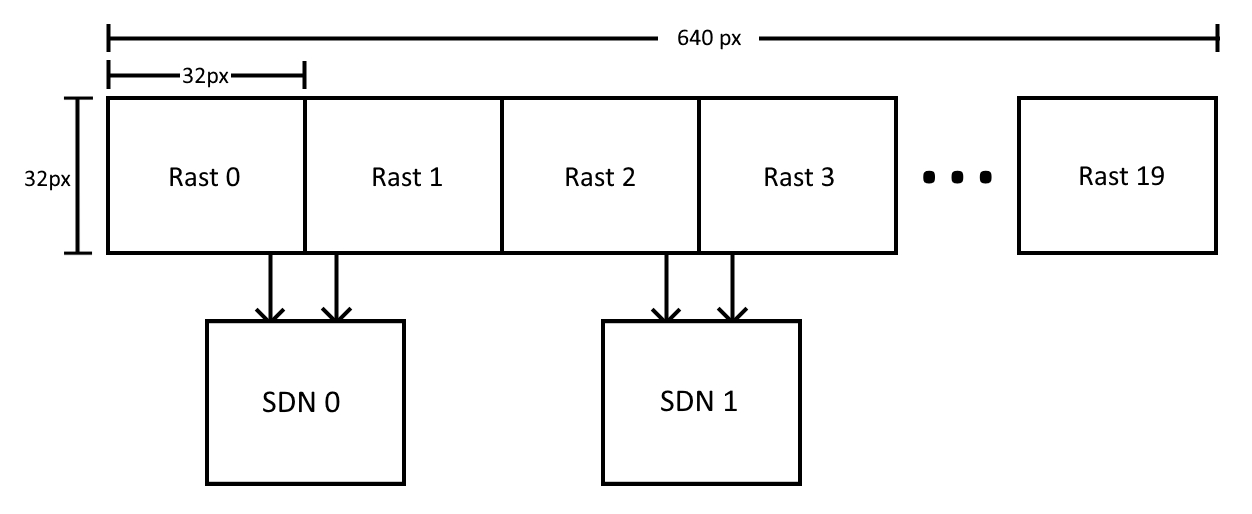
The high level view is that the screen is covered by 8×8 pixel tiles. A triangle setup block takes in triangles, culls ones that are fully offscreen or backfacing, calculates the edge functions and AABB, and then passes that information to a tile distributor that distributes triangle-covering tiles to rasterizers depending on the coordinates of the tile. There are 16 rasterizers, each processing eight rows of eight pixels at a time, and therefore tiles finish in 8 clocks, assuming no backpressure from the pixel FIFOs. Rasterizers are also responsible for tiling data before writing, in the case of non-linear render targets. This is because texturing is forced to use a specific tile mode, and I wanted to support render to texture. Render target width can be any power of two between 32 and 512, or 640 in the fullscreen case. Height is the same, except it’s fullscreen value is 480.
Compare this to the previous rasterizer, which was a “tile racing” design. A 640 wide screen was covered by a row of twenty 32×32 tiles, and each tile was handled by a rasterizer. It was similar to beam racing in that you had until HDMI scanout finished the previous tile row to rasterize triangles. Rasterizing to dedicated BRAMs was a great way to not have to deal with DDR3, but it was limiting in terms of performance. The design also didn’t support texturing, programmable render target sizes, tiled render targets, and a large offscreen buffer area to avoid having to clip triangles that were partially offscreen.
I am currently targeting 200MHz but thinking 150MHz is more realistic.
Terms and Definitions
Confession: I am garbage at deciding on terms to use and sticking with them, so parts of this blog post may deviate a little from what I use here, but I figure its still useful to at least pretend I am consistent.
Rasterizer: an 8 pixel wide adder that calculates edge functions, tests which pixels are inside the triangle, tiles data, and exports
Screen Tile: an 8×8 pixel tile. A 640×480 render target would be covered by 80×60 screen tiles. Each screen tile currently uniquely maps to a specific rasterizer
Row: primarily used to mean one 8-pixel row of a rasterizer or screen tile, but occasionally refers to a whole render target row. I thought about using “screen tile row” and “rasterizer row” to be more clear, but those are super tedious to type out. I seem to also freely use vector for this as well
Row Address: eight pixel rows are what is written to memory, and this address is just the row number in the order they are stored in memory. They are converted into byte addresses when passed to the DDR3 FSM
Block: tiled textures and render targets are made up of microtiled 4×4 pixel blocks that are then arranged in macro blocks. I use block instead of tile, because I already associate “tile” with “screen tile”. And if you want to know how confusing the rest of this post is going to be, just see how much I managed to mix up block and tile in the last two sentences alone!
Very Quick Maths Review
todo: edge functions, determinants, normalising barycentrics. Do I really need this? I feel like its one of those things everyone already knows, and that others have explained better than I could do in this crappy section.
Triangle Setup
Signed Fixed Point Review
Signed fixed point works exactly like you’d expect. Each type has a sign bit, some number of whole bits, and some number of fractional bits. So for example, take the s.3.5 format number 0.010.01000. It has a sign bit of 1’b0 (unsigned), a whole part of 3’b010 (2 in decimal), and a fractional part of 5’b01000 (1/4 in decimal), and so would be 2.25. If the sign bit was set, it would contribute a value of -8, and so the new value would be -8 + 2 + 0.25 = -5.75. Both addition and multiplication just work as long as all operands are signed, although for addition the decimal places must align as well. In general, adding two N.M format numbers results in N+1 whole bits and M fractional bits, and multiplying A.B and C.D needs at most A+C whole bits and B+D fractional bits. However, depending on the expected input data range, you might be able to get away with fewer bits.
Coordinate Systems And Internal Types
Inputs to triangle setup are normalised [-1..1], but verts that are offscreen can have values outside of that. Input vertices are s.1.14 format, leading to a possible range of [-1.99987792969 .. 1.99987792968]. This extra buffer space is to avoid clipping in some cases. Anything outside that range will result in “interesting garbage”, and needs to be clipped.
Render target width can be programmed to any power of two between 32 and 512, or 640 in the fullscreen case. Likewise, height can also be programmed to use the same powers of two, but its fullscreen value is 480. And so when converting to pixel coordinates, the worst case that I need to take into account is ±640 in the X direction, which requires log2(640)=10 bits to represent the whole part. And so pixel coordinates are in s.10.5 format.
There are two kinds of tile coordinates, each with a different purpose. Signed tile coordinates come from dividing pixel coordinates by 8, and are clamped from -40..39 for a 640 wide render target. These are mainly used to get the edge function starting X and Y values for the triangle AABB. The other tile coordinates are unsigned, and would go from 0..79 for a 640 wide render target. These are used to calculate which screen tiles need to be sent to rasterizers.
Tom Forsyth had warned me that going through every single expression, calculating its possible range, and working out the minimum bits needed was the path to madness. Sadly he told me this after I had spent over a month doing exactly that.
Since most of these are fairly simple, I’ll only bore you with one example, and that’s calculating the edge function C. As mentioned above, C is v0x * v1y – v0y * v1x. Pixel coordinates are s.10.5, and so v0x * v1y would be s.10.5 * s.10.5, and therefore need at most a s.21.10 result. For the subtraction, s.21.10 – s.21.10 would need at most s.22.10, and this would be the type needed to store C.
However, looking at the actual possible data range, the multiply only requires log2(640 * 480) = 19 whole bits, meaning the multiply result can be stored as s.19.10, saving two bits. Is it really worth it? Often, no. But in my first GPU, one bit was sometimes the difference between needing one [adder|LUT|multiplier] and needing multiple in serial, making routing harder and increasing the datapath length. If I had to do it all over again, I would just use the max bits to hold an expression, and then go back and optimise later, especially if I fail timing.
However, it’s not all this simple. Multiplication grows not only the whole bits, but the fractional bits as well, and it’s sometimes a bit challenging to know how many bits to keep without introducing too much error or growing the result too much. And both the reciprocal and the normalised edge functions require a totally different method of working out how many bits are needed to keep the accumulated error to an acceptable level as you walk screen tiles.
Main Pipeline
The main pipeline is responsible for calculating all the things that the tile distributor needs to distribute tiles to rasterizers, such as the edge function A, B, and C for each edge, the determinant for backface culling, the AABB to cover the triangle, the starting value of each edge function for the starting tile, and the determinant reciprocal for normalising.
Stage 0
To minimise the number of multiplies, I process one edge per clock rather than all three at once. And so I can only accept a new triangle at most once every three clocks. If a new triangle hasn’t been seen for three clocks, and a new triangle comes in, stage zero begins by converting the input triangle verts to pixel units, and calculates some offscreen flags using normalised coordinates. Pixel unit conversion depends on the current programmed render target size, whether its width or height, and whether it is fullscreen or power of two. The power of two case is pretty simple, and just involves some shifting
Fullscreen is a bit more annoying as it involves a multiply that can’t be expressed as a single shift. However, luckily it can do the multiply with just two shifts and an add.
// kRenderTargetResolutionFull means 640, and goes from [-320..320]
function PixelCoord Ndc2Pixel_Width(RenderTargetResolution dim, NdcCoord v);
if (dim == kRenderTargetResolutionFull) begin
// x320, which is x256 + x64, in other words:
// (1.1.00000000000000 << 6) + (1.1.00000000000000 << 8) =
// 0) move decimal point right by 6, 1.1.00000000000000 => 1.1000000.00000000
// 1) move decimal point right by 8, 1.1.00000000000000 => 1.100000000.000000
// 2) add 2 frac bits to (1), and sign extend (0) by 2 bits to line up the decimal points
// {1100000000000000, 2'b0} = 1100000000.00000000
// {2{v[15]}, 1100000000000000} = 1111000000.00000000
// 3) add together, grow result by 1 bit, result is 1.1011000000.00000000, keep r[18:3]
// [1.1011000000.00000]000 = 1.1011000000.00000 = -320
automatic logic signed [$bits(NdcCoord)+2-1:0] a = {v, 2'b0};
automatic logic signed [$bits(NdcCoord)+2-1:0] b = {{2{v[kNdcCoordSignBit]}}, v};
automatic logic signed [$bits(NdcCoord)+3-1:0] temp = a + b;
automatic PixelCoord retval = temp[18:3];
return retval;
end else begin
return Ndc2Pixel_P2(dim, v);
end
endfunction
Calculating the all/any offscreen flags is best done on s.1.14 normalised coordinates, since they are resolution independent and the check only takes two bits. This is because something >= 1 will have a zero sign bit and a whole bit of one. Something < -1 will have a sign bit of one and a zero whole bit
This is used to calculate whether any and all verts are offscreen. If all vert X or Y values are offscreen, the entire triangle is discarded. If any vert X or Y values are offscreen, this signals later stages that the final AABB needs to be clamped to the onscreen area.
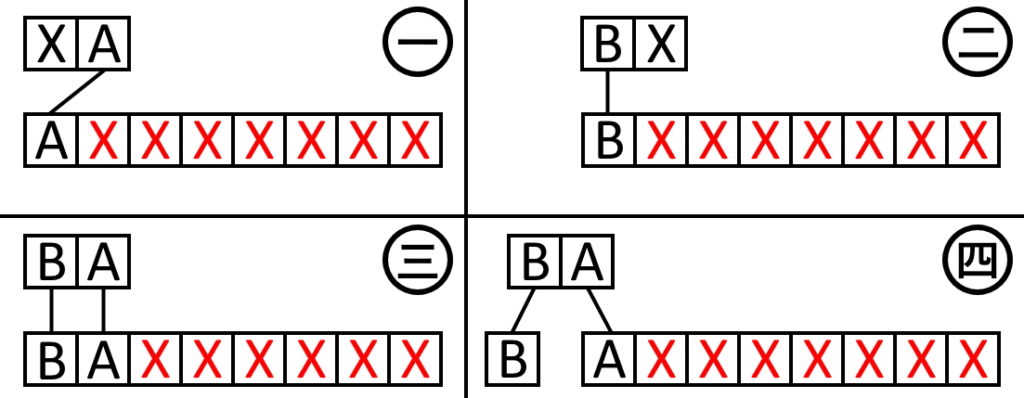
If stage 0 is currently processing a triangle, it does quite a few things. First of all, it takes the previously cached vertices and rotates them such that they go {v2, v1, v0} => {v0, v2, v1} => {v1, v0, v2}. This means the verts I care about are always in verts[0] and verts[1], and allows me to calculate edge functions for {v0, v1}, {v1, v2}, {v2, v0} on three consecutive clocks. It also shifts a three bit which_edge signal from 001 => 010 => 100. This can be used as the write enable signal for the three per-edge FIFOs that store edge functions.
Next, it begins the determinant calculation by doing v1x – v0x, v1y – v0y, v2x – v0x, and v2y – v0y. Not only are these the differences used in the determinant, but they can also be reused as the -A and B coefficients for the current edge’s edge function. The calculation of C is also started here, specifically the two multiplies in v0x * v1y – v0y * v1x.
Finally, to start the AABB processing, I first need to convert from pixel coordinates to tiles. The conversion is a simple signed shift of the pixel coordinates by 8 bits: 5 bits to remove the fractional bits and 3 to divide by the tile size. Next, I take the min and max of the first two vertices X and Y tile numbers, and pass along the third vert’s tile numbers for processing in the next stage.
Stage 1
Stage 1 is quite a bit simpler. It takes the determinant differences computed in the previous stage, and does the multiplies. This corresponds to (v1x – v0x) * (v2y – v0y) and (v2x – v0x) * (v1y – v0y). It also finalises the calculation of C, taking the previously computed (v0x * v1y) and (v0y * v1x) and taking the difference (v0x * v1y) – (v0y * v1x). Lastly, it finalises the unclamped AABB calculation by taking min and max of the vert 2 tile coordinates, and the previously calculated vert 0 and 1 tile min/max.
Stage 2
Stage 2 takes the AABB and clamps it to the onscreen area. At this point, like pixel coordinates, the tile numbers are centered around zero, and the valid onscreen area I clamp to goes from [-40..39] for width and [-30..29] for height in the fullscreen case. Stage 1 passes only the max tile number for the current resolution, and so the minimum is obtained by negating the bits in the max. That is ~39 = -40, and ~29 = -30. These min tile numbers are then passed on to the next stage as well.
Fun fact: I can get away with only four checks here. For example, I only need to worry if the minimum X is left of the screen edge, but not the maximum X. If the maximum X is left of the screen edge, the triangle will be discarded, and so it doesn’t matter what I calculate here.
Stage 2 also finalises the determinant by taking the products computed in stage 1 (v1x – v0x) * (v2y – v0y) and (v2x – v0x) * (v1y – v0y), and computing the difference (v1x – v0x) * (v2y – v0y) – (v2x – v0x) * (v1y – v0y).
Stage 3
Stage 3 is where the magic happens and things start coming together. With the offscreen flags computed in stage 0 and the determinant in stage 2, I have everything I need to know to determine if I am going to discard the triangle. If all vert X values or Y values are offscreen, or if the sign of the determinant is negative, then nothing is added to the FIFOs. Note the determinant check is currently only looking for a set sign bit, but I could easily introduce one bit of render state that can be compared to the determinant sign to allow programmable anticlockwise/clockwise culling.
So if at least part of the triangle is on screen, and the determinant is positive, then three things happen. First, the min tile numbers computed in stage 2 are subtracted from the AABB to shift to unsigned tile coordinates. In the fullscreen example, tile coordinates go from -40 .. 39, where -40 is the left edge of the visible screen and 39 is the right edge. And so subtracting the offset of -40 from the tile coordinate -40 is zero, shifting the AABB area from 0..79. These shifted tile coordinates are then added to a FIFO for later consumption by the tile distributor.
Next the edge function -A and B values are added to the current edge’s FIFO. This is where the pipelined which_edge signal comes in. It is a three bit onehot signal, where each bit is used as the write enable for one of the edge function FIFOs. That allows me to know which edge’s data is arriving, and write to the corresponding FIFO. I don’t add C, because -A and B are the X and Y pixel increments, and only these are needed by the tile distributor and rasterizers. However, C will be used in the next stage to calculate the edge function starting values.
The edge function multiplies, -Ax and By, are also calculated here. But rather than use X and Y in pixel units, I multiply with the AABB minimum tile coordinates. This saves some bits and logic, but I have to multiply by eight in the next stage to get the real function
Lastly, the determinant is passed to the reciprocal unit. This, shockingly, takes the reciprocal of the determinant which is used in barycentric normalisation.
Stage 4
Stage 4 calculates the final unnormalised edge function values. It takes the -Ax / 8 and By / 8 from stage 3, and does By – -Ax + C. First I subtract -Ax from By, and then pad the result with three bits to go from tiles to pixels. The result has 5 fractional bits, but C has 10, and so I discard the LSB5 of C before adding it to the previous difference. The result is the edge function evaluated at the start of the first tile in the AABB. And like before, the three bit which_edge signal will be used in the next stage as the write enable for the per-edge FIFO, allowing me to know which edge is being processed on a particular clock.
Stage 4 also calculates the row and column components of the render target address, in units of 8 pixel rows, of the start of the AABB. The column offset is just the X tile number of the left edge of the AABB. Row offset, however, depends on screen resolution. The number of eight pixel rows per scanline is width/8, and there are 8 rows per tile, so as I move down by one tile, the address changes by width/8*8. The row component of the address then becomes tile_y * width/8*8 = tile_y * width. The limited allowed render target widths means I can dodge doing the multiply.
Stage 5
Rasterizers are currently eight wide, and so for some edge function value f, will process row
{f, f+1A, f+2A, f+3A, f+4A, f+5A, f+6A, f+7A}
Since there is still quite some of the reciprocal unit’s latency to hide, I figured I would precalculate this vector here. Stage 5 also calculates the row address increment when moving up one tile. Again, the number of eight pixel rows per scanline is width/8, and there are (currently) 8 rows per tile, so regardless of tile mode, the row address increment for the next Y tile is just resolution_x / kRasterizerTileWidth * kRasterizerTileHeight
Determinant Reciprocal
At the risk of disappointing you, the reciprocal uses a simple Newton Rap Son approximation. Robin Greene introduced me to some fantastically interesting papers and alternative ideas, which I hope to play around with later, but in the end my input data range was so constrained that I was able to get away with doing the simplest thing possible.
NR requires an initial guess to work properly. For the input range, I looked at the determinant for “reasonable” triangles. The determinant will never be greater or equal to one, will always be positive, and will be at most 2,457,600. In the initial implementation, I stored initial guesses in a 36kbit BRAM, with samples spaced 2048 apart. The table lookup value would have then been the whole part of the determinant shifted right by 11. This worked surprisingly well for values greater than 2048 where 1/x doesn’t change so fast, but was not great for smaller inputs. It also was wasteful, since the reciprocal is 26 bits, and therefore the table would store 1496 entries, or enough guesses for 3,061,760.
Attempt two was keeping the initial guess BRAM for values 2048 and larger, but using a simple approximation for smaller values. I noticed that for powers of two, the reciprocal was just a mirroring of the bits
I could then use the position of the most significant 1 (and the next bit as well) to find the closest power of two and use that as the initial guess. This worked far better than the first implementation for the initial guess, and was pretty light in terms of resource usage, but I thought I probably should do better.
In the end what I really wanted was a nonlinear distribution of samples in the table. More samples where 1/x changes the fastest, and fewer samples as the input gets bigger. But that would have made it hard to meet timing, so I settled for just dividing the table in two. The first 256 table entries hold the initial guesses for 0 .. 2047. That’s 2048/256 = one sample every eight whole values. Then, the next 1496-256=1240 entries hold the table values for 2048 .. 2,457,600. This not only produced great approximations, but max input the table supports will be 2,541,568. That’s enough for the max determinant 2,457,600 and far less wasteful than 3,061,760 used in the initial implementation. The final lookup table address becomes |input[21:11] ? 255 + input[21:11] : input[10:3].
The reciprocal unit is fully pipelined, and can accept one determinant per clock. This currently wastes a bit of logic, since at most a new triangle can arrive every three clocks, but I plan to optimise this later. Each NR iteration is three clocks to help meet timing, and I’m currently using 4 iterations although I could probably get away with less. The module input takes an unsigned fixed 22.10 determinant, a valid request flag to indicate a new triangle arrived, an unsigned fixed 0.26 reciprocal output, and a return flag indicating when valid output is on the bus. A separate always_ff block in the triangle setup block looks for the valid output bit, and adds the reciprocal to a FIFO which is read by the tile distributor.
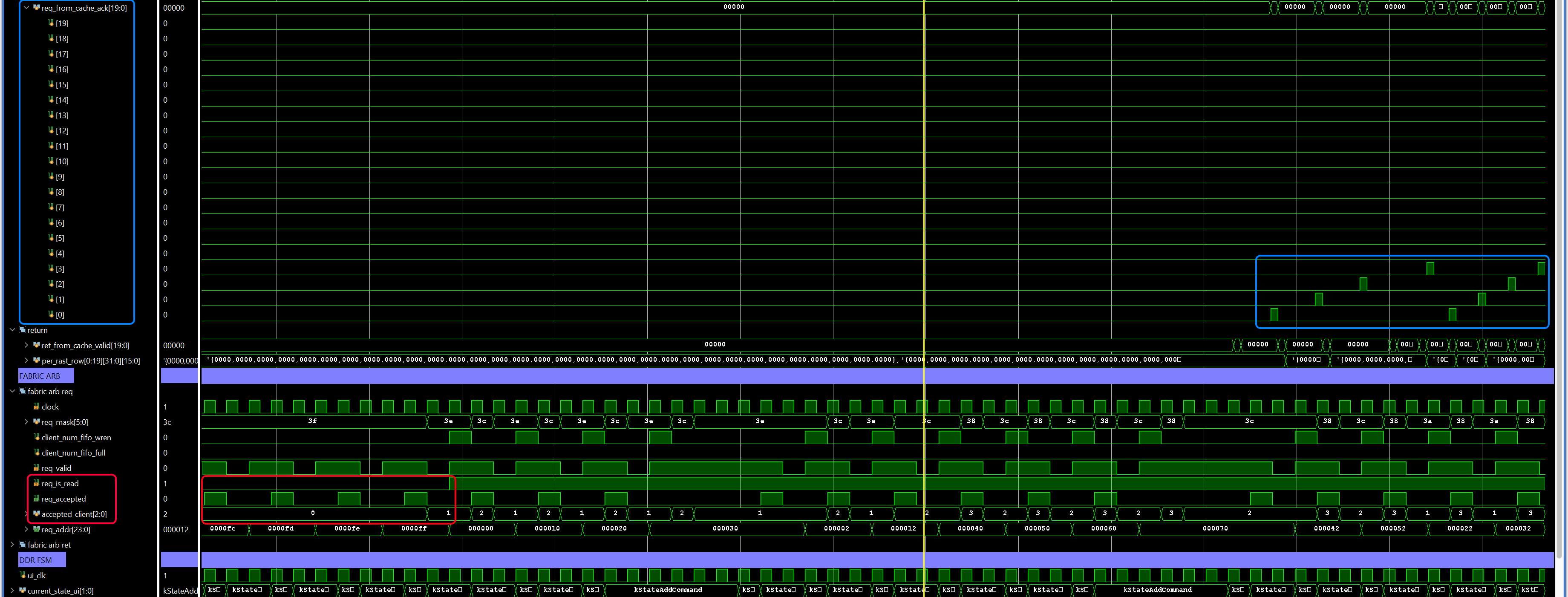
Tile Distribution
Tile distribution begins when the reciprocal FIFO is no longer empty. I don’t need to query the other FIFOs since reciprocal is the last to be written, and if it’s not empty then none of the others are empty.
Mapping Tile Coordinates To Rasterizers
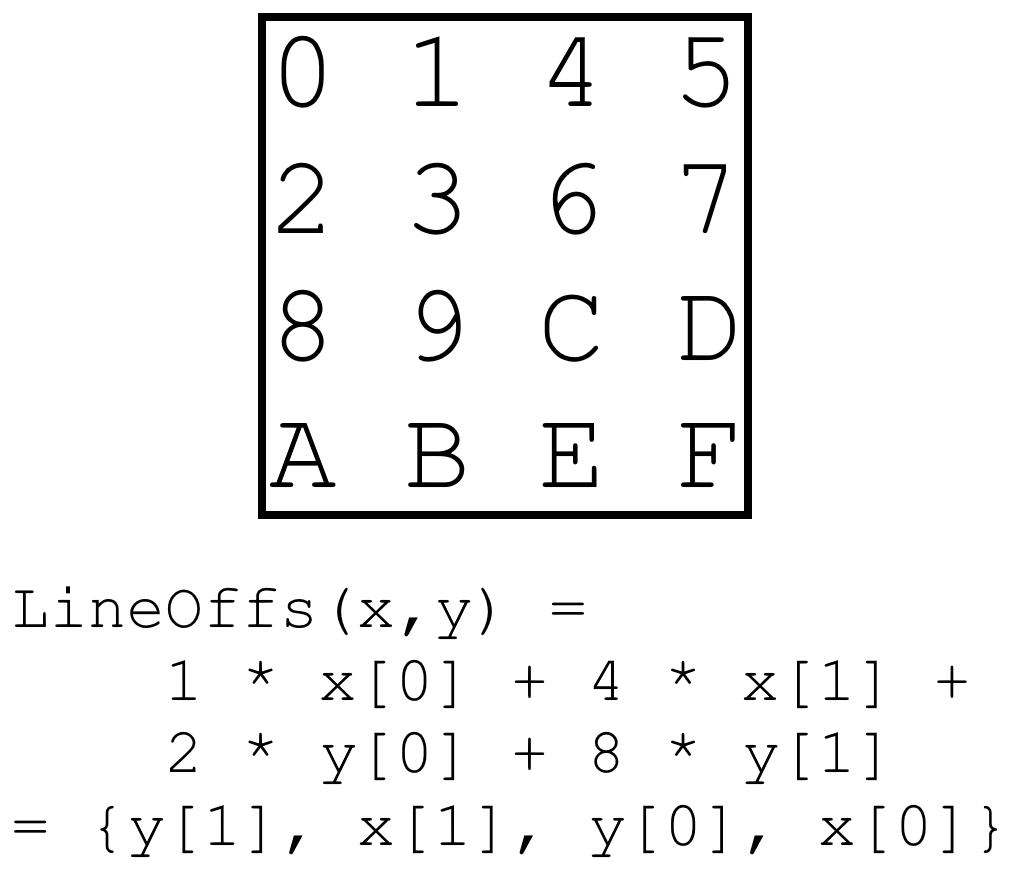
There was some debate as to whether a specific 8×8 screen tile should map to only one rasterizer, or whether any tile could freely be assigned to any free rasterizer. The latter is nice for parallelism in cases where multiple small triangles would have been contained in the same screen tile. However, since four rasterizers share a texture cache, there is also some value in making sure that tiles that are physically adjacent on screen map to rasterizers that share the same cache. In the end, hundreds of small triangles mapping to exactly the same screen tile seemed like a bit of an edge case, and so the tile X and Y coordinates now uniquely determine the rasterizer according to {y[1], x[1], y[0], x[0]}. A good compromise might have been being able to assign a tile to any rasterizer in a group of four, but that is an optimisation for another time.
Distribution Ordering
The order of tile distribution is a bit weird. Instead of moving across screen tiles in left to right and bottom to top order, I use a snake pattern where the X direction alternates between 1 and -1 for each tile row. This is partially for performance reasons, but mainly because doing it this way reduced some logic, making it easier to meet timing.
FSM
The FSM has two states: take in a new triangle AABB and distribute tiles to rasterizers.
Initialisation mainly caches off the data that triangle setup added to its FIFOs, however some adjustments for tilemode have to be made here. Because writes to render target memory are in terms of eight-pixel screen tile rows, addresses are actually just row numbers. When distributing a screen tile to a rasterizer, the rasterizer needs to know the row address of the first row in the screen tile, and the row address increment to use when going through the rows. For linear, rows that are contiguous in the X direction are also contiguous in memory. This means that the starting row address for a screen tile is screen_tile_y * render_target_width + screen_tile_x, and the row increment is width / 8.
In linear, rows that are contiguous in the X direction are also contiguous in memory. The address given is the number of the first row in the screen tile, and the row increment is how the address changes when moving through the screen tile’s eight rows
For tiled, all of the rows in a screen tile are stored contiguously in memory, and so the inner tile row increment is just 1. And since there are eight rows in a screen_tile, you see addresses incrementing by 8 as you move across the screen to the next tile in the X direction.
for tiled, all eight rows in a screen tile are contiguous in memory
The tile distribution state begins by calculating the target rasterizer from the tile X and Y coordinates, and then checking if that rasterizer’s input FIFO is full. If the FIFO isn’t full, it adds the screen tile row address, row increment, vector of eight edge function values, the B for each edge, and the current tile mode to the rasterizer’s input FIFO. It then moves right to the next tile, incrementing the vector of eight edge function values by 8A, and updating the row start address for the next tile. When the end of a tile row is reached, it moves up one tile, and starts moving left. It continues in this snake pattern until all screen tiles in the AABB have been distributed.
Rasterizers
There are 16 rasterizers, and each is 8 pixels wide. They are essentially wide adders, adding B to a vector of edge function values, checking which pixels are inside the triangle, tiling data if necessary, and exporting pixels and valid masks.
Pipeline
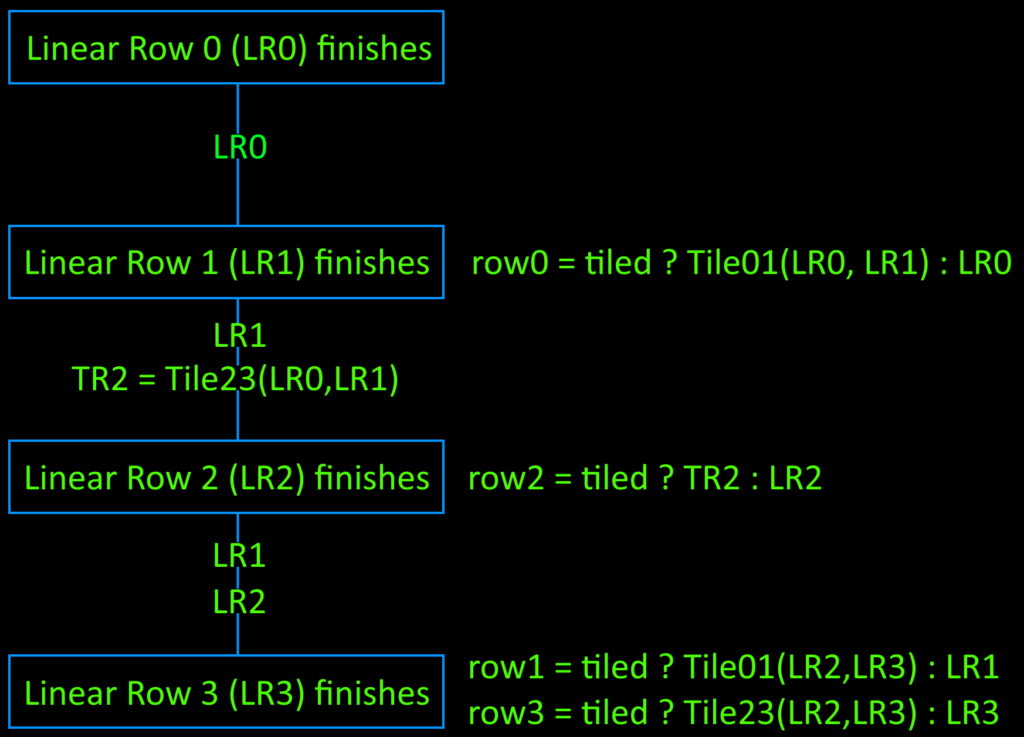
In this section, LR refers to linear rows, or the eight rows (per-edge rows of edge function values) produced by the adder for a screen tile. These are produced in LR0, LR1, LR2 … LR7 order, or the order you’d expect for a linear surface. Conversely, tiled rows are referred to as TR, and are produced by taking as input two linear rows and applying some tiling function. For example, TR0 = Tile01(LR0, LR1) means taking in linear rows 0 and 1, and producing a tiled row in the format TR0 or TR1 expects. There is also a Tile23() for producing TR2 and TR3.
A tiled block is 4×4, so an 8×8 screen tile needs to produce 4 blocks. If linear were the only supported tilemode, the 8 rows of these blocks could be produced in order, but tiled data makes it a bit more complicated. For the purposes of the diagram below, numbers indicate the order edge function values are produced by the adder, with 0..7 being the first linear row, 8..15 being the next linear row, etc.
both linear and tiled formats create a horizontal pair of blocks from four linear rows. The next block pair is created from the final four linear rows
There are two things to note. First, rasterizers create 4×4 blocks in horizontal pairs, over four input rows. To simplify the logic and ease timing, rasterizers process the first four linear rows, building up the first horizontal block pair and writing the resulting rows to four row FIFOs for later consumption. The second block pair is then constructed from input rows 4..7, and also added to the FIFOs. This is fully pipelined, and there is no stall between the creation of the lower block pair and the upper block pair.
The other thing to note is that the stages in which output rows can be determined is different for linear and tiled. Linear can produce a complete output row every clock, while tiling rows requires two different linear rows as input. From the diagram below, you can see that calculating tiled rows 0 and 2 requires linear rows 0 and 1, and calculating tiled rows 1 and 3 requires linear rows 2 and 3.
rasterizer pipeline diagram, showing when output rows can be computed, and what data is needed
Stage 0
Stage 0 is where the 24 adds (8-wide row x 3 edges) happen. If this is the first row in a screen tile, the edge function starting values for the screen tile’s first row are fetched from the input FIFO and passed to the next stage, otherwise the row is incremented by B and passed on.
Stage 1
In stage 1, the first linear row (LR0) becomes available, but TR0 requires both LR0 and LR1 to calculate, so LR0 is just passed through to the next stage.
Stage 2
In stage 2, LR1 finishes, meaning I now have the data needed to produce TR0 and TR2. TileRow01(LR0, LR1) tiles the data, and the resulting TR0 is muxed with LR0 as row_fifo_din[0] = tiled ? TileRow01(LR0, LR1) : LR0.
I also have the rows needed to create TR2, so I call TileRow23(LR0, LR1) to pre-tile the data, and pass it on to the next stage when LR2 will become available.
Stage 3
LR2 becomes available here, so I use the previously tiled TR2 to calculate row_fifo_din[2] = tiled ? TR2 : LR2. Both LR1 and LR2 are passed on since they will be needed in the final stage.
Stage 4
Stage 4 is the final stage, where LR3 becomes available, and the remaining two output rows can finally by calculated. This means row_fifo_din[1] = tiled ? Tile01(LR2, LR3) : LR1 and row_fifo_din[3] = tiled ? Tile23(LR2, LR3) : LR3. Because row_fifo_din[3] is the last FIFO to be written, the export block uses ~row_fifo_empty[3] to determine when all four rows of a block pair have been added.
Export
Export reads the four rows of a tile pair from the four row FIFOs, and appends them together into all_rows. This way, all_rows[0] is always the row I care about, and each clock I can just shift all_rows right by the size of one row to get the next row.
For each row, I look at the sign of the three edge functions. If all sign bits are zero, then the pixel is inside the triangle. Rows where all eight pixels are outside are discarded here. Valid rows are sent to a two stage arbiter, where the first stage arbitrates between the four clients in each rasterizer group according to a rotating priority, and the second stage arbitrates between the four groups.
Demo Structure
Because I am a weak human who is afraid to try a test of everything together before I try out lots of smaller targeted tests, the demo is stripped down from the final GPU in a couple of ways. かんにんしとぉくれやす!
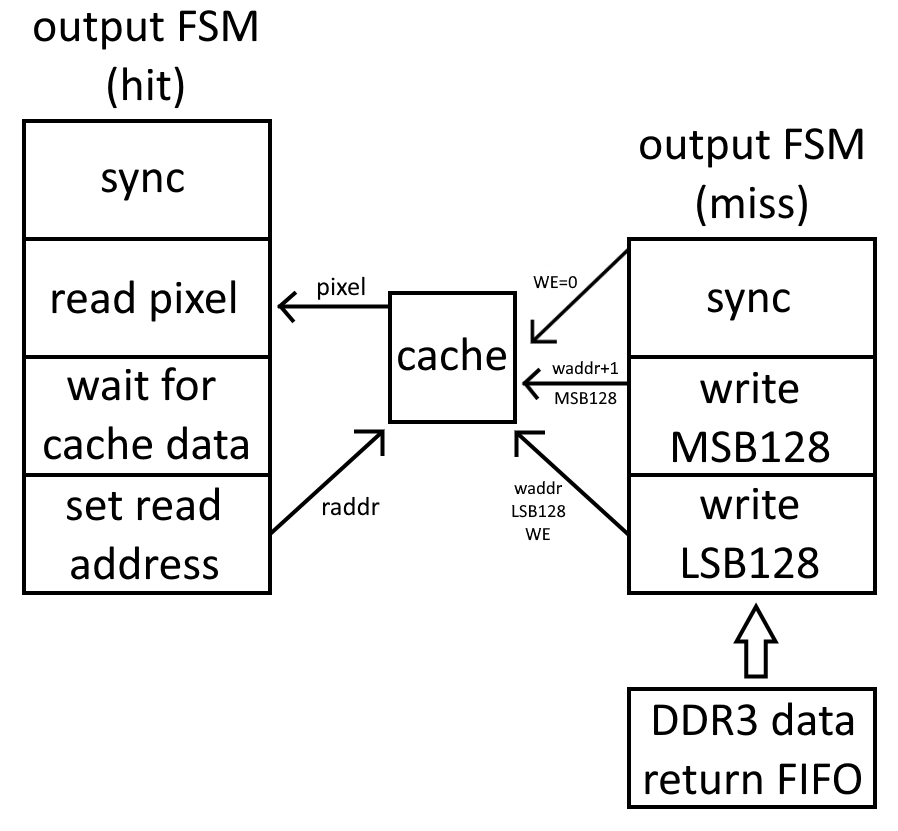
Pixel shaders aren’t hooked up yet. Rather I went for a temporary fixed function type thing where rasterizers export rows directly to memory for HDMI scanout to consume
Texture units and the texture caches aren’t hooked up in this demo.
There is one render target, and it starts at a fixed address of 0. Renders to render targets of different size all just alias this area, which is sized large enough for the maximum RT size (640x480x16bpp)
There is one texture, and its address is fixed to be at the end of the render target area. I know I already said texturing wasn’t hooked up yet, but render to texture is the very next test I want to try
The final memory fabric is there, but only render target and scanout clients are hooked up.
There is still lots of perf tuning and balancing of the memory fabric to be done, as right now I am doing some pretty naieve things
I got so sick of making diagrams in paint dot net, that I literally started drawing them by hand. I haven’t written this much by hand since I had to write my address kanji 3x at the bank
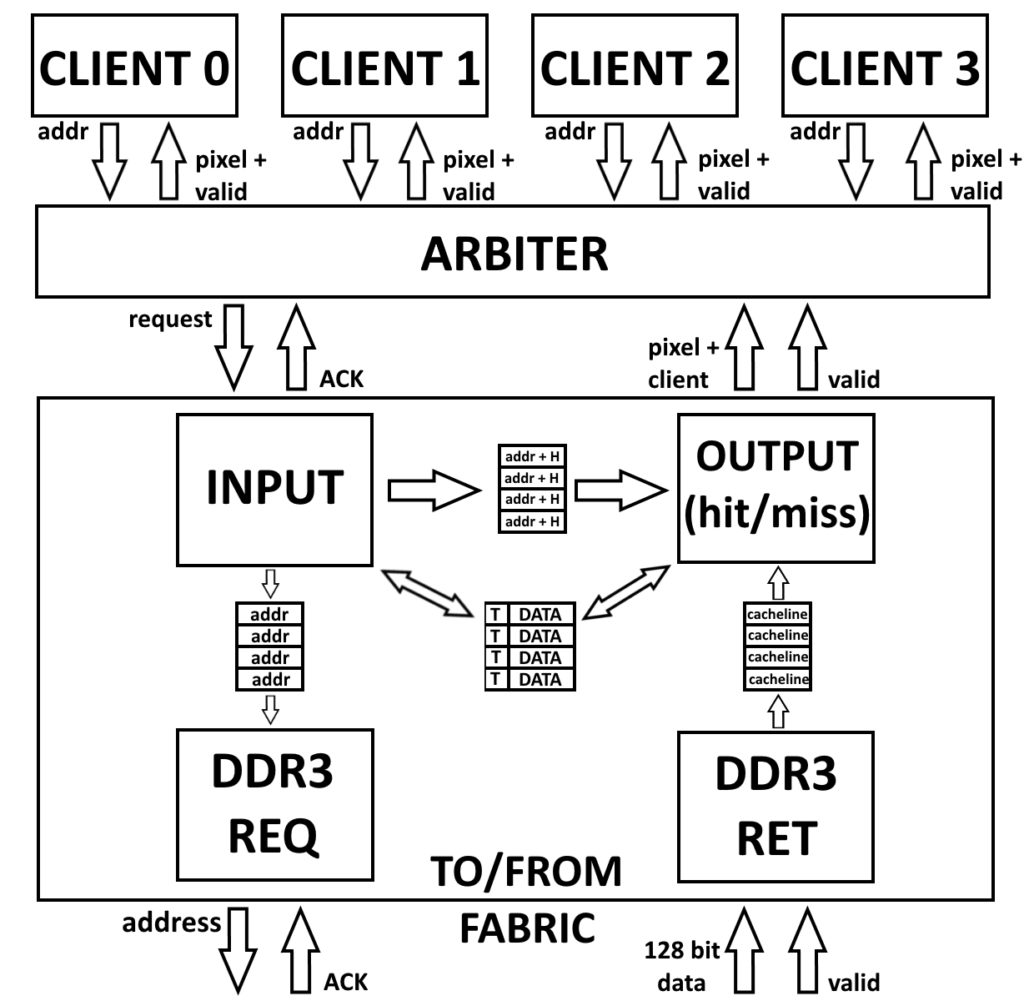
In the above image, each of the four rasterizer groups feed into an arbiter that selects a client request from the four attached rasterizers. That request is then fed to the RT group arbiter that selects a request from one of the four groups and passes it to the DDR3 arbiter. The other three DDR3 arbiter clients are scanout, texture read requests, and texfill, with scanout having the highest priority, and texfill having the next highest.
FAQ
Is this how real GPUs work? I’ve never seen a line of professional RTL in my life, but I am willing to guess the answer is no. It feels like how you’d design something for FPGA architecture is different than how you’d design for ASICs and proper chips, and the scale of what you can do is smaller on FPGAs. Also professional GPUs have the additional advantage of being coded by professional RTL engineers… which I am most certainly not. No seriously, I have no idea if what I am doing is weird, normal, sane, or insane.
What is the speed of light / expected perf? TODO once I get more perfcounters in there
Will you add [depth|mipmaps|stencil|compute|cubemaps|depth compression|colour compression|whatever]? If you have features you want me to add, please give me your twitter name and I will block you.
Will you support Games Pass? Yes, in that a friend once asked me if I intend to make Games, to which I replied “Pass”
Did you release this blog post on 12月3日 on purpose? Not at all, since 一二三でゲームが変わらへん
Warning: this block entry is constantly being updated as I think of things to add. If you have questions or things you think should be covered, please leave them in the comments below.
概要
The Arty A7 comes with 256MB of DDR3L, but actually using it isn’t always the simplest thing. Unlike the Zync series, there is no hard IP for memory controllers, and so you have to roll your own or use Xilinx’s soft IP. There is no one definitive guide (that I could find), and there is quite a bit of wrong information out there. Much of the needed info either doesn’t exist, is spread out all over the internet, or assumes a good deal of previous FPGA experience to understand. So therefore, I am writing this blog post as a place to hold all my notes, because I will most certainly forget all of it in the near future.
Requirements for following along are: an Arty A7 board, Vivado (I am using 2021.1), Windows 10, infinite patience for dealing with Vivado’s bugs, and way too much free time to read a super long and dry blog post that explicitly spells out every step of the process.
Controller Levels
Vivado uses IP called MIG for generating DDR controllers. MIG stands for Massively Insufferable Garbage, and is basically a GUI where you specify the parameters of your memory, and it crashes… err, I mean creates a controller for you. There are four levels of controller this blog post mentions, but sadly the only two that MIG can create are AXI and UI. However, the UI controller can be used as a base for creating your own native controller.
AXI
The MIG IP gives you the option to generate an AXI interface. AXI is, to directly steal text from wikipedia, part of the ARM Advanced Microcontroller Bus Architecture 3 (AXI3) and 4 (AXI4) specifications, and is a parallel high-performance, synchronous, high-frequency, multi–master, multi-slave communication interface, mainly designed for on-chip communication. If that sounds like your jam, then AXI might be for you.
UI
UI is the other interface that MIG can generate. It’s a bit high level and allows you to add read and write commands fairly easily, while handling things like data reordering and user address mapping for you.
Native
UI is a convenience wrapper on top of the native layer. If you don’t need some of the UI helper functionality, such as reordering requests, you can get better latency by going with native directly. The MIG manual has some very sparse details on how native is supposed to work, but sadly MIG has no option to generate a native-level controller. The best option I’ve come up with so far is generating a UI controller, and then modifying the generated IP to make it do what you want
PHY
This is the real live boy. At the PHY level, you are worrying about temperature, refreshing cells, and directly driving memory signals. Not recommended for beginners, but I purposely chose a board with no DDR controller hard IP in the hopes that someday working out how to write a controller at this level. I am nowhere near that yet. Give me a few years.
DDR3 Refresher
This is meant to serve as a quick refresher of things that would be useful to know when generating and using the controller. It is in no way meant to be a exhaustive explanation of the inner workings of DDR3 or SDRAM
Structure
DDR3 consists of ranks, banks, rows, and columns. The A7 is a single rank configuration, and so the rank number will always be 0. Each rank consists of 8 banks, each bank is made up of 2^14=16,384 rows, and each row is made up of 2^10=1024 columns. Therefore the total number of columns would be 8 x 16,384 x 1024 = 134,217,728. If we have 256MB of memory, that’s 256MB / 134,217,728 = 2 bytes, or 16 bits per column which is what we’d expect.
Address Encoding
All this row and column business is important for performance reasons. To use a row, it must first be opened which can take some of time. Each bank can have one row open, but not multiple rows per bank. Once a row is opened, subsequent accesses to it’s columns are less expensive, but as a general rule you don’t want to be unnecessarily opening a new row every access. Vivado’s memory controller generator gives you two options for address encoding: {row, bank, column} and {bank, row, column}. In {row, bank, column}, you go through all 1024 columns and then increment the bank. Because there are 8 banks, this gives you one giant contiguous working area of 8 banks x 1024 columns x 2 bytes/column, or 16,384 bytes that can be randomly accessed without having to reopen a row.
Address encoding {bank, row, column} is useful in a different situation. Instead of each bank contributing a row to form one big contiguous area, here each bank has its own 32MB area, of which only one 2048 byte row can be open at a time. This can be useful in situations where you have different memory fabric clients that need to access their own far apart PA regions, and once you open a new row you’re unlikely to need the previous one. So as an example, maybe I have a texture at address 0 that I (mainly) linearly go through and bring into the cache, so that I’m unlikely to need previous data. And at the same time I have a render target located 32MB after the texture that I write to semi randomly, and I don’t want it to interfere with rows that the texture reads are using.
Banks vs Bank Machines
Just to be clear, the number of banks != the number of bank machines in the controller. For an example of how this can affect performance, I’m going to directly quote Xilinx:
Increasing the number of Bank Machines can improve the efficiency of the design. For example, if a traffic pattern sends writes across a single row in all banks before moving to the next row (writes to B0R0, B1R0, B2R0, B3R0 followed by writes to B0R1, B1R1, B2R1, B3R1), five bank machines will provide higher efficiency than 2, 3 or 4. Requests for each bank in Row0 can be assigned to the first four Bank Machines. When the request comes in for Row1, requiring a Precharge/Activate, the 5th Bank Machine can be assigned this request while the other Bank Machines complete any pending requests
In my controller, I left the default number of bank machines at 4, but that’s just because I haven’t done any profiling yet to see if my memory access patterns could benefit from additional bank machines.
Generating The Controller
Digilent is kind enough to provide MIG-loadable project files containing the DDR parameters, however MIG import is horribly broken. It will do things like ignore the clock period defined in the project and just set something else. Therefore it’s probably best to just manually enter everything yourself. You might even learn something along the way. You will still need the UCF file containing the pin constraints for the board. It can be downloaded here.
With that downloaded, go ahead and open the Memory Interface Generator in the IP Catalog. On this first screen you’ll want to select Create Design (because we’re not importing a project), set a component name for your controller, set the number of controllers to 1, and make sure that AXI4 is unchecked. Hit next, and enter in the FPGA part number, which should be xc7a100t-csg324. Hit next again and select DDR3 SDRAM.
There is quite a bit to enter on the next page. The clock period should be set to 3000ps, or 333.33MHz. Set the PHY to controller ratio to 4:1, the memory part to MT41K128M16XX-15E, the memory voltage to 1.35v, and the data width to 16. Ordering should be normal, number of bank machines is 4, and enable the data mask if you think you’re going to need it.
On the next page, set the input clock period to 6000ps (166.666MHz), the read burst type to sequential, and output driver impedance control and RTT to RZQ/6. It’s up to you if you want to use a chip select pin and what address mapping you want to use.
some of the more cryptic DDR3 settings live here
The above page is where stuff starts getting interesting. First up, we need to choose configurations for the system clock and reference clock, with options like single-ended, differential, and no buffer. Differential is for differential pairs, single ended is useful for when we directly connect to an external clock pin, and no buffer is probably what you want if you are deriving your clocks from a clocking wizard (like me!). This naming always threw me off, because “no buffer” sounds like it can’t be used with clock buffers. Rather it means there is no clock buffer, so feel free to use your own. So let’s just say we set these both to no buffer and move on. It will save you having to track down obscure clock backbone errors in implementation.
System reset polarity can be anything you want, as long as you remember what you chose later when we hook up the controller. Maybe its just best leave it as its default, active low. Debug signals should be off, unless you somehow really need it. Then turn on internal vref and IO power reduction. Finally, XADC instantiation is turned off in the suggested settings, but what do they know?! Go ahead and enable it unless you are using the XADC block somewhere else in the design. Click next to go to the next page and set the impedance to 50Ω.
We’re almost done now. On the next screen, choose Fixed Pin Out, and hit next. Then click Read XDC/UCF and browse to the UCF file you previously downloaded. Click on the validate button to validate, and you should be greeted with a popup saying the current pinout is valid. Here’s a funny story. If you had imported the Arty project instead of entering all the above settings manually, this step would fail with alot of very scary sounding warnings. Aren’t you glad you did it all manually?
The final config screen asks you to select pins for sys_rst, init_calib_complete, and tg_compare_error. Honestly, this screen is for fancy people who want to hook things up to actual pins for some reason. Leave all of these unconnected, and we’ll hook them up to logic later. After this, its a bunch of summary screens, disclaimers clearing Xilinx of any liability if your device explodes, and accept prompts. Blow through all these and you will have yourself a shiny new memory controller.
Using The Controller
So you have a controller generated, but what now? Hooking it up is easier than you might think. Note that this is just for synthesis, as the process for simulation is quite a bit more complicated, and will be explained later in this post.
Hooking It Up
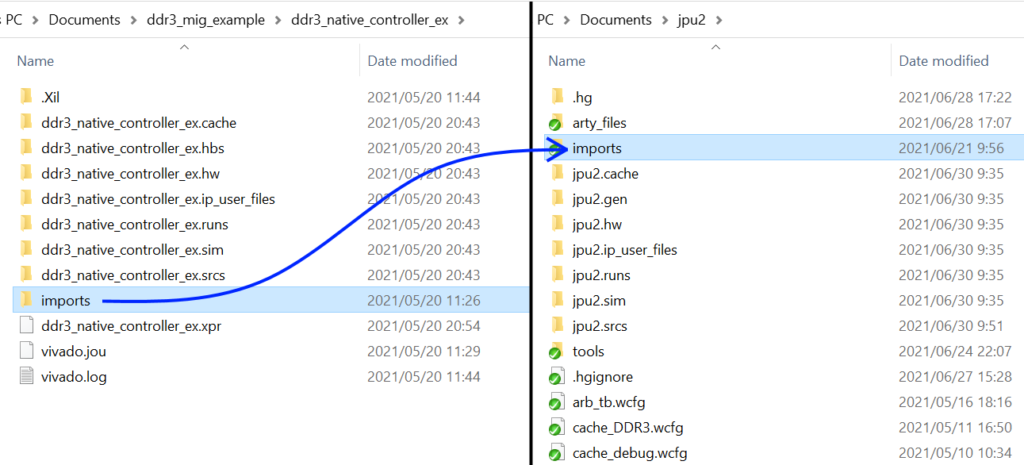
Go to your top module, and add the following DDR3 signals to your module ports.
The clever among you will notice that normally the names of signals in your top level module come from your constraints file, but none of these DDR3 signals are in Arty-A7-100-Master.xdc. This is because MIG generates a second secret constraints file that isn’t added to the project. I named my controller ddr3_native_controller, and so the constraints file would be something like ddr3_native_controller.xdc, and its stored around jpu2.gen\sources_1\ip\ddr3_native_controller\ddr3_native_controller\user_design\constraints\.
The other thing to note is those params at the top. Where they come from will make a bit more sense once we get to the section on simulation. But for now, its fairly safe to use them as-is if you stick to the controller settings outlined above.
To actually instantiate the controller, just do this
The controller takes in two clocks and outputs one. The input clocks are a 200MHz reference clock, and a 166.666MHz system clock, both of which can be generated by a Vivado clocking wizard. These are refclock_200MHz and sysclock_166MHz in the above code. The output clock is ui_clk, and is the clock that the user interface part of the controller runs on. So any logic you have that drives controller signals should be clocked on the positive edge of this depressingly slow 81.25MHz clock.
Assuming you chose for the reset signal to be active low, you have to hold sys_rst low for a minimum of 200 nano, before bring it high again. You can do this any way you want, but I usually do something silly like this
// reset delay is something like 200000 pico (or 200 nano)
// so 100MHz clock has a period of 10 nano
// and so we can just hold it low for 20+ clocks
logic [4:0] reset_cnt = 1;
always_ff @(posedge CLK100MHZ) begin : DDR_RESET
// count up until we wrap around to zero, and then stay there
reset_cnt <= reset_cnt + |reset_cnt;
sys_rst_n <= ~|reset_cnt;
end : DDR_RESET
assign sys_rst = RST_ACT_LOW ? sys_rst_n : ~sys_rst_n;
Paths
There are two different paths to the controller: one for writing commands and another for adding the data you want to write to memory. These paths are (semi) independent in that you can add write data before or at the same time as you add the corresponding command. You can also add write data after you add the command, but it must be within two clocks of adding the command.
Command Path
The command path deals with writing commands, and any signals that are common to reads and writes. To issue commands, set the command number, the address, and assert app_en. This path can randomly become unavailable as the controller performs various internal functions, so you have to always check app_rdy the clock after setting your data to know if you need to continue holding or if the command was accepted. To make this a bit clearer, here is a sample waveform to illustrate.
In the above example, app_rdy transitions from 1 to 0 on the exact same clock as a write command is being added. If we were to sample app_rdy on that clock, we’d get the old value (1) and mistakenly think the command would be accepted. Therefore we have to start checking app_rdy the clock *after* we set command data.
Signals
app_rdy: output, indicated whether a command could have been accepted the previous clock
app_in: input, indicates to the controller that we're adding a command
app_cmd: input, 1 for reads and 0 for writes
app_addr: input, the address of the read or write command we are adding
ui_clk_sync_rst: output, active low signal indicating the UI is ready to use
init_calib_complete: output, active high signal indication DDR3 calibration is complete
Write Data Path
The write data path is basically a FIFO holding 128 bit data to be written to memory. Like the command path, it also has a signal to indicate when data has been successfully added, but unlike the command path’s app_rdy which can ho high and low at random times, app_wdf_rdy is basically there to tell you if the write data FIFO is full, and won’t suddenly go low unless you add data. This makes it a bit easier to work with.
Signals
app_wdf_rdy: output, indicates the write data FIFO isn't full, and new data can be added
app_wdf_wren: input, write data FIFO write enable
app_wdf_data: input, the 128 bit write data to be added to the FIFO
app_wdf_mask: input, per-byte write enable mask. Active low
app_wdf_end: input, must always be tied to app_wdf_wren, despite what the incorrect docs say
This explains the timing requirements. Because write data is just added to a FIFO, it can be added before or together with a write command. When a write command is encountered, a few clocks later the write path will get the data to be written from the write data FIFO. Like I said before, its possible to add the write data up to two clocks after the write command, but I’ve not tried that before and it feels like you’re asking for trouble.
Performance
Simulation
This was initially a bit confusing for a dumb reason. With most other IP, you set it up, generate it, instantiate it, and it all just works both for synthesis and for simulation. The memory controller is a bit different because controller != memory. You need both the controller IP *and* the DDR model for it to work, or else the controller will sit around forever waiting for calibration. Sadly the info on how to make this work isn’t easy to find (or I am garbage at searching)
opening an example design from the sources view
The first step is to right click on the controller IP in the sources pane, and go to Open IP Example Design. Save it somewhere, and go to that directory in explorer. You’ll see a subdirectory called imports, which you’ll want to copy and paste to the root directory of your project.
copy the imports directory from the sample design to your design
Some tutorials I have seen say it’s ok to only copy some of the RTL files, but it’s probably safer to just copy everything and then remove what you don’t need. Next, add wiredly.v, ddr3_model.sv, and sim_tb_top.sv to your project’s simulation sources. You may need to add some of the other sources as well, if you get errors about undefined modules. Then, set sim_tb_top to be the new top module for simulation.
My new simulation hierarchy. sim_tb_top from the example DDR design is my new top module, and sim_top is the old one containing my testbenches
We’re almost done. Essentially what we’re going to do is to let that new top module from the sample design handle all the DDR stuff for us, but inside of it we instantiate our old top module and pass the relevant DDR signals. Search sim_tb_top.sv for the section that says FPGA Memory Controller , and just below you’ll see a module called example_top being instantiated. Replace example_top with the name of your previous simulation top (sim_top in the above image), and modify the module to take the DDR signals passed in from sim_tb_top. So my sim_tb_top.sv now looks like this
// this is sim_tb_top.sv. Its the file that came from the generated reference design.
// it used to instantiate a module called example_top, but I replaced that with my sim_top
//===========================================================================
// FPGA Memory Controller
//===========================================================================
sim_top u_ip_top(
// DDR signals here
and my sim_top.sv looks like this
// this is in sim_top.sv
// it's my old top module before I made sim_tb_top the new top module.
// I also modified it to add all the DDR signals
module sim_top(
// DDR3 signals from sim_tb_top
inout wire logic [DQ_WIDTH-1:0] ddr3_dq,
inout wire logic [DQS_WIDTH-1:0] ddr3_dqs_n,
inout wire logic [DQS_WIDTH-1:0] ddr3_dqs_p,
output wire logic [ROW_WIDTH-1:0] ddr3_addr,
output wire logic [3-1:0] ddr3_ba,
output wire logic ddr3_ras_n,
output wire logic ddr3_cas_n,
output wire logic ddr3_we_n,
output wire logic ddr3_reset_n,
output wire logic [1-1:0] ddr3_ck_p,
output wire logic [1-1:0] ddr3_ck_n,
output wire logic [1-1:0] ddr3_cke,
output wire logic [(CS_WIDTH*1)-1:0] ddr3_cs_n,
output wire logic [DM_WIDTH-1:0] ddr3_dm,
output wire logic [ODT_WIDTH-1:0] ddr3_odt,
// clocks. todo: these need to be generated
input wire logic sys_clk_i,
input wire logic clk_ref_i,
// misc
input wire logic [11:0] device_temp_i,
output wire logic init_calib_complete,
wire logic tg_compare_error,
input wire logic sys_rst);
// your code here!
endmodule
And that’s it! Those signals can be hooked up to your DDR3 controller, and you should be in business. There are three things to note, though. First of all, simulation can take a Very Long Time. Like minutes or more of wall clock time can pass before DDR calibration finishes, so be prepared to wait unless you disable calibration. Second, you’ll notice I have input ports for sys_clk_i, clk_ref_i, and sys_rst. The top level simulation generates these signals for you as a convenience, so you’re free to use them in simulation, but it’s probably a better idea to just use what’s described in the clocking section above. And finally, you’ll notice I don’t have any of those module parameters such as DQ_WIDTH, ROW_WIDTH, and CS_WIDTH that you’ll see in your version of the files. So that I can use them all over, I pulled all the parameters into a header file (ddr3_params.vh) that is included anywhere it’s needed. I suggest you do the same.
Interfacing With Native Directly
Signals and Flow
It’s probably useful to begin with looking at the general flow of native mode
demonstration of the native interface protocol
native interface flow
native interface processing for read and write data. The wr_data timing shown is incorrect
The timing diagrams are fairly self explanatory, but I’ll go over the general usage anyway. To add a command, on clock N set the command data. Command data is the command itself, priority bit, data_buf_addr, and the address in {rank, bank, row, column} form. This is the first difference between native and UI. When creating the controller, you chose a mapping from user address to bank, row, and column, and the address encoding was handled by the UI layer. But with native you have to manually specify these yourself. Next, on clock N+1, assert the use_addr signal to indicate a request wants to be added. If accept was asserted, then use_addr can be safely deasserted on clock N+2.
図1-65 shows the flow for adding multiple simultaneous commands. Assuming the command data is set on clock N, you still assert use_addr on clock N+1. If accept is high at that time, then it’s OK to move on to the next command data. You can see this when the command data transitions from 1 to 2 on clock N+1. Things get more interesting on clock N+3. use_addr is asserted and the command data wants to transition from 3 to 4, but it can’t because accept is low. Therefore the command data must remain stable until accept goes high.
The biggest difference between UI and native has to do with data_buf_addr. Because the native layer can reorder requests for efficiency, it needs a way to signal to the user design which request is being referenced. For writes, data_buf_addr might be an index into a user buffer that stores the data to be written. For reads, it might be an index into a user buffer where we will store data returned from memory for reordering.
This is illustrated in 図1-66. For writes, wr_data_en is a signal from the native layer that indicates it is pulling the write data for a previously added write command. wr_data_addr will be the same as the data_buf_addr we added with the command data. You’ll notice that while the write data is 128 bits, write data D0~D3 (the first 16×4=64 bits) is read from the user buffer on the first clock, and D4~D7 (the last 64 bits) on the next clock. To make this easier to handle, the native layer also provides wr_data_offset, which will be 0 during the first 64 bits and 1 during the last 64 bits. When wr_data_en is high, it’s your job to take wr_data_addr and wr_data_offset and use them to look up the write data for the command. This write data is used to drive wr_data.
Reads function similarly. rd_data_en indicates that the native layer is returning read data to you. rd_data_addr is an echo of the data_buf_addr you added with the read command, rd_data_offset will be 0 for the lower 64 bits and 1 for the upper 64 bits, and rd_data is the 64 bits of read data being returned from memory. Once you receive the data, its up to you to reorder it if that’s something you care about.
Corrections
First of all, a confession: I probably should have said this earlier, but while the above descriptions do match the timing diagrams shown in the docs, they don’t match the actual Arty A7 DDR3 configuration. The diagrams assume a burst length of 4, meaning data is returned 16×4=64 bits at a time. But we have BURST_LENGTH set to 8, or 16×8=128 bits, meaning we only need one read/write per request, and both rd_data_offset and wr_data_offset will always be zero. To be fair to Xilinx, this is called out in the docs, as the description of wr_data_offset specifically states
このバスは、バースト長の処理に1サイクル以上が必要なときに使用します
You can see all this in the waveform below.
I should also mention there a few confusing errors in 図1-66. First of all, rd_data_addr is listed twice. The second one obviously should be rd_data_offset. Next, the way the write timing is shown is incorrect. It seems to imply that you are supposed to provide the write data on the same clock that the system tells you the buffer address to pull it from. Surely that can’t be right. 図1-64 seems to get it right, since wr_data_en and wr_data_addr are provided on clock N, and you’re expected to provide the corresponding write data on clock N+1. This can be seen in the following waveform
waveform from the lower level DDR3 controller. Notice how the write data changes one clock *after* wr_data_en goes high
Here you’ll see wr_data_en go high the same clock that wr_data_addr comes (red circle). And it one clock after this that the user buffer provides the data to be written to memory (blue circle).
How The UI Layer Does It
The UI provides a (possibly overcomplicated?) sample implementation for the read and write buffers. These are located at user_design\rtl\ui\mig_7series_v4_2_ui_rd_data.v and user_design\rtl\ui\mig_7series_v4_2_ui_wr_data.v respectively. I recommend taking a look through these to see what they are doing, or at least reading the extensive comments for a pretty good description of how they work. Actually, while you’re there, check out all the source for the IP. Everything is in there, even PHY.
As a bit of starting advice, before you go modifying the UI, try setting the controller data ordering to STRICT. Much of the UI latency comes from read reordering, which is turned off in by the following line
The obvious caveat is that you need to understand your memory access pattern *and* profile, to see if you can get 0) away without reordering and 1) can actually benefit from a reduction in latency. But if you’re not concerned with latency, then why are you still reading this?
Every console has that one iconic thing that appears in tech demos. PlayStation has the duck in a bath, Microsoft has the red ring of death, and I have The Cort In The Hat
このサイトのコンテンツは個人の意見で会社を代表しません
Cache Details
概要
This post represents my first attempt to implement the simplest possible texture cache that still works with my current GPU, in preparation for getting texturing working. Originally, it wasn’t meant to be a releasable post, but rather was written before coding the cache as a way to work out the high level design ideas and to find potential issues. Turns out pretending to explain my ideas to a fictional reader works really well for me as a way of designing. As a bonus, it’s also a way to help me remember how my own stuff works, should work get busy and I need to come back to the project after N months. The cache is currently working both in sim and in hardware, but with fake values stuffed into memory instead of actual textures
Cache Organisation
The texture cache is a read-only cache with LRU policy and single-clock invalidation. The cacheline size is 256 bits, which is 16 pixels in 565 format, representing a 4×4 tiled block. The data store for the cache is built out of pairs of 36 kbit simple dual-port BRAMs. This appears to be a requirement stemming from the cache having asymmetric read and write sizes (one pixel reads and half cacheline writes). This gives a total memory size of 72 kbits, or 256 lines, if ECC isn’t repurposed as usable data. And with a 2-way cache, that is 128 sets. Therefore read addresses presented to the cache will have 4 bits indicating the pixel within a line, 7 bits to determine the set, and the MSB 16 bits will be the tag
Figure 1: a cacheline is a 4×4 block of pixels. Hex numbers represent the offset inside a cacheline
The tags are kept separate from the cache datastore. Each line has a 16 bit tag, and a valid bit, and each set has shares one bit to indicate which way is LRU. This data doesn’t represent the actual current state of the cache, but rather the state the cache will be in once the next request is processed.
Figure 2: high level cache view. T is cache tags and LRU bits, H is a bit indicating hit or miss, and DATA is the cachelines
Client Arbiter
Each cache serves four clients. To give me the simplest test, the clients are currently just the rasterizer tiles, although eventually I may try to add texture reads to my pixel shaders. Each client can have multiple requests in flight, and data is returned in the order that requests are accepted.
The arbiter chooses a client request with a simple four bit rotating onehot mask, where the set bit determines the first client to consider. So if the mask was 4’b0100, the arbiter would start with client 2, and then try 3, 0, and 1 in order, looking for a valid request. A mask of 4’b0010 would check clients 1, 2, 3, and then 0. The priority mask is rotated one bit left when a request is accepted. Early on I tried to be more “clever” with arbitration, favouring client requests that would be hits before ones that would be misses, but this really complicated the design and made it harder to meet timing. It also starved the cache of DDR3 requests that could have been in flight.
The arbiter itself is a two state machine. In the first state, it looks for a valid client request. If one is found, it saves off the request address and client number, presents the request to the cache, rotates the accept mask, and notifies the client that it’s request was accepted, before transitioning to the second state. The second state simply waits for the ack from the cache, which usually comes within two clocks unless the cache input FIFO is full or it’s not in the request accept state.
Requests consist of only an address and client ID. Because we have 256MB of RAM, the full address width is 28 bits. However, cache requests are for 16 bit pixels, meaning the LSB of the address isn’t needed in the request, and so request addresses are 27 bits wide. Client ID is just a 2 bit number indicating client. This ID is returned by the cache, along with the pixel data, and is used to signal a client that there is valid data for them on the bus.
Cache Input Processing
The cache itself is made of four state machines: input, DDR request, DDR return, and output. The input machine is a three state FSM where the first state accepts and saves off an incoming request from the arbiter, the second state gets the tags and LRU bit for the relevant cache set, and the third state updates the cache tags, adds misses to the DDR3 request FIFO, and adds the request to the output request FIFO.
The output request FIFO entry contains a client number, one bit to indicate whether a request is a hit or miss, and some address information. Cache reads are pixel aligned, and so the read address is constructed as {set_bits (7b), way (1b), pixel bits (4b)}. Writes are half cacheline granularity, and so the addresses are {set_bits (7b), way (1b), halfline (1b)}, but the halfline isn’t needed until a miss’s data is returned from the memory fabric, and therefore isn’t stored in the output request FIFO entry.
The cache tags and LRU bits are stored separately from the cacheline data, and don’t reflect the current state of the cache. For example, a miss will set the valid bit so that the next request for the address will be a hit, even though the data is not yet in the cache. The cache is updated with the following pseudocode:
input_is_hit is a two bit vector (one for each way), that is guaranteed to be either zero in the case of a miss, or $onehot for a hit. The bitwise-or reduction of this, |input_is_hit, indicates whether the request hit in any way. In the case of a hit, the set’s LRU bit is set to input_is_hit[0], so that LRU is now set to whatever way we didn’t hit in. Otherwise for a miss, the current LRU bit is just inverted. The tag_entry is always updated, either with the existing tag for a hit, or the new tag for a miss.
DDR3 Request Processing
In the case of a miss, the input FSM adds memory requests to a CDC FIFO for the DDR3 request FSM to consume, with the write side clocked at the system clock frequency, and the read side clocked at the much lower DDR3 controller user interface frequency. The DDR3 request addresses are just the upper 23 bits of the byte address. This is because byte addresses are 28 bit and cache request addresses are 27 bits (since pixels are 2 bytes), but I want DDR3 request addresses to be cache line aligned. With a cache line holding 16 pixels, this means DDR3 request addresses only need 28 – $clog2(2) – $clog2(32/2) = 23 bits. It is this 23 bit address and the number of 128 bit reads (two for a 256 bit cacheline) that is sent over the fabric.
The DDR3 request FSM is a simple two state machine. The first gets an entry from the DDR3 request FIFO, if there are any. The second state presents the request to the memory fabric, and waits for the ack to come beck before getting the next FIFO entry.
DDR3 Return Processing
Data returned from the memory fabric is 128 bits wide, but cachelines are 256 bits, so I have some logic to gather the returned data into cachelines before adding to the return data FIFO. This is actually really simple, and just requires a single bit to indicate whether incoming data is the high 128 or low 128, and a 128 bit vector to store the previously returned data. And so the return data FIFO input becomes {new_data_from_ddr, prev_data_from_ddr}, and the FIFO write enable is (valid_data & is_high_128).
Output Block
Here’s where I admit I have been lying. The output FSM is actually two FSMs: one for hit processing and another for misses.
Hit FSM
The hit machine has four states. The first state waits for a valid entry in the output request FIFO. Once output_fifo_empty goes low, the request is saved off, the cache address is sent to the BRAM, and it transitions to the second state. All the second state does is transition to the third state, to give the BRAM time to return the requested data. In the third state, the output pixel is read from the BRAM, and it transitions to the final sync state.
Figure 3: output block hit and miss FSMs
Miss FSM
The write machine only has three states. Like the read machine, the write machine initial state also waits until output_fifo_empty goes low, but it also waits for (was_hit | ~ddr3_ret_fifo_empty). This is because in the case of a hit, the write machine has nothing to do and can safely continue. But in the case of a miss, it also has to wait until the required data is returned from the memory fabric. Once the condition is met, the cacheline data is read from the DDR3 return FIFO. The lower 128 bits of that data, the cache write address, and the write enable bit (high if the request was a miss) are sent to the BRAM, and it transitions to the second state. In the second state, the BRAM address is incremented and the upper 128 bits of the cacheline are sent to the BRAM. Like the read machine, the final state is the sync state, which waits for both FSMs to enter into sync, before transitioning back to the first state.
SVA Verification
The bulk of architectural asserts in the cache are for verifying FIFOs, checking for overflow, underflow, and validity, and making sure that the FIFO element sizes match what was set up in the IP. The rest are sanity checks verifying the expected flow of the various FSMs. For example, if an output request FIFO entry is a miss, once the data from memory is available, the cache write enable should rise, stay asserted for two clocks, and then fall. There are also quite a few internal consistency asserts, such as making sure a request never hits in more than one way, that valid bits go low one clock after an invalidation, DDR return FIFO must be empty if the output request FIFO is empty, and that data from the cache is valid exactly two clocks after a read request.
There are some asserts in the arbiter as well. Most of these are sanity checks like the accepted client must actually have a valid request, the client request bit goes low one clock after the arbiter accepts a request, and that the arbiter FSM must be in the kArbStateWaitCacheAck state when the cache asserts arb2cache_if.req_accepted. I bring these three up as an example because all three of the were failing due to a stupid typo that I feel really should have been an error, or at least a warning. Thanks, Vivado. The lesson here is to assert everything, no matter how stupid or small it may seem.
Finally, testbench asserts are used to verify correct high level operation. Each test has three modes: linear, all misses, and alternating ways. Linear uses linearly increasing addresses, and verifies both that the data returned is correct and that I get 1 miss followed by 15 hits. The all misses mode requests the first pixel of every cacheline, and so asserts check that every request is a miss. Alternating ways is a bit harder to explain. Basically I want to test
[tag A, set 0, way 0: miss]
[tag B, set 0, way 1: miss]
[tag A, set 0, way 0: hit]
[tag B, set 0, way 1: hit]
[tag C, set 2, way 0: miss]
[tag D, set 2, way 1: miss]
[tag C, set 2, way 0: hit]
[tag D, set 2, way 1: hit]
[tag E, set 1, way 0: miss]
[tag F, set 1, way 1: miss]
[tag E, set 1, way 0: hit]
[tag F, set 1, way 1: hit]
and so on. That pattern is used to go through all of memory, cycling through all sets and ways, and then wrapping around. I then assert that req_was_hit == test_counter[1], since this pattern should give two misses followed by two hits. One caveat is that the tests above only apply to testbenches where the arbiter has one client. Things get harder in the four client case, since the client request order is randomised. I can still verify the returned data is correct, but since I can no longer rely on any client being the first to touch a cacheline, it becomes harder to verify hits and misses. But this is definitely on my list of things to do
Future Optimisations
Like I said, this represents a first attempt at getting something simple up and running, and in doing so I took quite a few shortcuts. Currently, data is returned in the order requests are accepted, and a miss can block subsequent hits. I’m considering having per-client queues in the cache, where requests from a particular client are always processed in order, but there is some freedom to return a hit from client A while client B’s miss is pending. I actually looked into this pretty early on, but it really complicated the design. I may have to come back to this in the future if I am feeling brave
Fake Scanout Demo
So, why fake a demo? Well, lighting up a green LED on test success is fine, but this is a “GPU” so it would be nice to see something visual on screen. The current rasterizer is a remnant from my previous tile racing design, and rewriting it to support texturing and framebuffers is going to take a Very Long Time. So in order to get some visual confirmation that the texture caches and memory fabric are working, I tried to come up with a minimal work demo that would get some textures displaying.
Demo Setup
I tried to keep the demo as close as possible to the final GPU configuration. So there are twenty “rasterizers”, each covering a 32×32 pixel tile, or a total area of 640×32. Four rasterizers share a texture cache, and so there are five texture caches. These five caches talk to DDR3 through a memory fabric arbiter, which is also shared with a single write client that fills RAM with tiled texture data stored in a BRAM. The addressing used is identical to the final addressing calculation, except that the texture width is locked to 256 pixels. The fake rasterizers themselves don’t do any rasterization. Rather they only contain two state machines: one for requesting the needed texels and the other for receiving them from the cache.
High level demo config. 20 rasterizers connect to 4 caches
DDR3 Fabric and Arbiter
To save time, the memory fabric arbiter is based on the cache client arbiter, but with some modifications. The biggest of these is that there are now both read and write clients, the number of clients is increased from four to six, and the priority is now fixed based on client number. In the demo, client 0 is the write client. It fills RAM with texture data and then goes idle forever, and so it’s given the highest priority to allow it to finish before any reads occur. For read clients, client 1 has the highest priority and client 5 has the lowest, since client 1 handles pixels on the left side of the screen which are needed before client 5’s right side of the screen pixels.
fabric arbiter. The red boxes show the write client’s last four writes finishing before read clients can start. The blue boxes show the cache 0 read clients locking out the other lower priority caches. Click to enlarge image.
The other major modification is that data coming back from memory can can consist of a variable number of 128 bit transactions, rather than always being one like for the cache arbiter, and so the transaction count (minus one) needs to be sent to the DDR3 state machine. For writes, I’m only writing 128 bits at a time, so the number of transactions is always one. For reads, this is currently always going to be two since the only read client is the caches, and caches want to fill 128×2=256 bit cachelines.
When a read request comes along, the requesting client number is put in a FIFO. When data comes back from memory, a return transaction counter is incremented, and when the counter has all bits set, the client number FIFO has its read signal asserted to move on to the next entry. This allows me to add the client number to the FIFO once, even though I’m expecting two transactions back.
DDR3 State Machine
The memory controller has two separate and (semi) independent paths: a command path that takes a command (read or write) and address, and a write data path for storing data to write. The write data can be added before the command, on the same clock as the command, or up to two clocks after the command is added. But because the command path can become unavailable (app_rdy goes low) for long periods of time, it was safer to always add the write data first, if its a write command. And so the state for adding write data looks like
app_en <= 0;
calibration_success <= 1;
read_transaction_count <= from_ddr3_arb_if.read_transaction_count;
app_addr <= (from_ddr3_arb_if.req_addr << kDdr3ReqAddrToFullAddrShift);
app_cmd <= from_ddr3_arb_if.req_is_read;
// if a valid read comes in, or a write comes in and there is space in the write data FIFO
if (from_ddr3_arb_if.req_valid & (from_ddr3_arb_if.req_is_read | app_wdf_rdy)) begin
app_wdf_wren <= ~from_ddr3_arb_if.req_is_read;
from_ddr3_arb_if.req_accepted <= 1;
app_en <= 1;
current_state_ui <= kStateAddCommand;
end
And the state for adding commands (one per transaction) just becomes the following simple loop
// but requests consist of multiple contiguous transactions, so count down
read_transaction_count <= read_transaction_count - app_rdy;
app_addr <= app_addr + (app_rdy << kTransactionIncShift);
app_en <= ~app_rdy || |read_transaction_count;
current_state_ui <= app_rdy && (read_transaction_count == 0) ? kStateWaitRequest : kStateAddCommand;
The return data logic simply waits for app_rd_data_valid to go high and then assigns from_ddr3_arb_if.ret_data <= app_rd_data and then from_ddr3_arb_if.ret_valid <= app_rd_data_valid;
Fake Rasterizers
These aren’t really rasterizers, as they don’t do any rasterizing, but rather are just stand-ins for the 20 rasterizer tiles I will eventually have to update to work with texturing. For now, think of them as just FSMs that request and receive texels from the texture caches.
Cache Request
The request FSM begins when receiving a signal from HDMI, and requests 32 contiguous (in X) texels from the texture cache. Texture data is tiled as shown in figure 1, and therefore the texel address is computed as
// shouldn't really require any muls and adds. Everything is just a vector insert
function TexCacheAddr PixelXyToCacheAddr(input FakeTexCoord x_in, input FakeTexCoord y_in);
return (x_in >> 2) * 16 // start of 4x4 tile in a row
+ (y_in >> 2) * (kFakeTextureWidth * 4) // start of 4x4 tile in a col
+ {y_in[1], x_in[1], y_in[0], x_in[0]}; // offset inside the tile
endfunction
Once all 32 requests are accepted by the cache, the FSM transitions to idle and waits for HDMI to signal the next scanline’s data is needed.
Cache Return
The return FSM waits for data to come back from the cache, and builds up a per-rasterizer vector of the last 32 texels returned.
logic [kNumRastTiles-1:0] ret_from_cache_valid;
generate
// sadly Vivado won't let you index into interfaces with for loop variables
for (tg = 0; tg < kNumRastTiles; ++tg) begin
assign ret_from_cache_valid[tg] = cache_client_ifs[tg>>2][tg&3].ret_valid;
end
endgenerate
// per rasterizer cache read
always_ff @(posedge clock_in_200MHz_rasterizer) begin : PER_RAST_READ
for (int t = 0; t < kNumRastTiles; ++t) begin
if (ret_from_cache_valid[t]) begin
// {old_pix, new_pix} = (old_pix << 16) | new_pix
per_rast_row[t] <= (per_rast_row[t] << $bits(CachePixel)) | ret_data_from_cache[t >> $clog2(kNumClientsPerTextureCache)];
end
end
end : PER_RAST_READ
Here per_rast_row[t] is the per-rasterizer vector of 32 texels that is eventually passed to scanout to be used as the colour data. ret_from_cache_valid[t] is asserted if the cache is returning valid texels for client t, and ret_data_from_cache is the per-cache returned texel data.
HDMI Scanout
HDMI processing is largely unchanged from previous GPUs. There are three clock domains: a 25MHz pixel clock, a 250MHz TMDS clock, and a clock that runs at the GPU system clock. That final one is responsible for interfacing between scanout and the rest of the GPU.
The interface block is the most “interesting” bit. It signals the fake rasterizers to start requesting texels when
This because to request texels for line N, I want to get them from the cache during line N-1, which means kicking everything at the end of line N-2. Here, gHdmiHeight is 525 lines, and so I want to start when the line == 523 or when line < 480-2.
The interface block also signals the fake rasterizers to latch or shift out the fetched texels, shift register style. The latch happens when
To process texels for line N, I want to latch them during the previous line (N-1). So for 525 lines, latch scanline 0’s texels at the end of line 524, wrap around, and then end with latching scanline 470’s texels at the end of line 478. Once the row of pixels is latched, the interface block can shift out one texel per clock, and add it to a very small CDC FIFO. This data is then consumed by the 250MHz block which pulls the final colour to be scanned out from the shared FIFO.
Results
Alternate demo mascot: rirakkuma
My desk is a chaotic mess
A fun historical note
This post was published on 2021/06/27. Last night I was banging my head against a wall (figuratively) trying to figure out the final RTL bug in the texturing demo. I woke up, having apparently dreamt the solution, ran to my computer and confirmed the fix. Finally being able to relax, I checked facebook where I was greeted with this amazingly timed memory from exactly one year ago today!
Exactly one year ago today I finished my last faked demo
So yeah, see you on 2022/06/27 for a faked depth buffer demo, I guess?
Special Thanks
As always, thanks to @domipheus, @CarterBen, @Laxer3A, and @sparsevoxel for keeping me inspired with their absolutely mental projects.Thanks to @blackjero for instilling in me the importance of debugging graphics by actually putting things on screen instead of stuffing numbers into buffers.
And super mega ultra thanks to @mikeev, @tom_forsyth, @rygorous, and everyone else participating in the twitter FPGA threads. Its an honour being able to ask such accomplished professionals so many stupid questions and not get laughed out of the room
Dokukon (独身コンピューター), also known as Hitokon (一人コンピューター)Bocchikon, and any other name that implies the opposite of ファミコン, is a 18 bit retro console mainly made in a weekend as part of a 48 hour console jam. It tries to stick to clock speeds that would have been plausible in the 16-bit era, with a few notable exceptions described in later sections.
The general design philosophy can be summarised as: I hate CPUs, and want to do everything I can to minimise CPU involvement in everything. The audio system uses command buffers that can play complex songs just by writing a single MMIO register. The scatter/gather pattern DMA is designed to transfer data to and from different source and destination patterns to avoid CPU loops. The start address of palette index and colour writes encodes a pattern so that every CPU write updates the destination address to the next location in the pattern.
Parts Used
Arty A7 100T board
HDMI PMOD
AMP3 Audio PMOD
Famicom Controller
The Arty can be purchased from Digilent here. The AMP3 PMOD is also from Digilent, and is sold here. Finally, the Famicom controller is just a regular Famicom controller with the connector cut off, and wired to PMOD-pluggable pins. See below for more info.
Scanout
This is the most major departure from the 16-bit era clock speed goal. The screen is fixed at 640×480 @ 60Hz, for which the HDMI spec requires a 25.175MHz pixel clock and a 251.75MHz TMDS clock. The HDMI block is responsible for signalling the GPU both when new scanlines start, and N clocks before a scanline starts, where N is the latency of HDMI => GPU messages. The GPU then adds colours to a pixel colour FIFO which scanout then reads from and displays.
Audio
Audio output is fixed at 16 bits per channel, two channel stereo, and a 24,000Hz sample rate. This is driven by a 768KHz bit clock, and an MCLK of 6.144MHz that drives the audio logic. Technically it could be clocked much lower, but good luck getting a PLL/MMCM to generate a clock in the kilohertz range
Audio is programmed via GPU-like command buffers stored in audio RAM. There are per-channel CPU-accessible MMIO registers responsible for setting the command buffer address, pausing and unpausing the audio, and setting volume, with more registers currently being added. The currently available commands are
square wave: Play a note from C3 to B5, for a length of time between a whole note and sixteenth note, including dotted
set BPM: set the channel BPM. Supported range is 50 to 177
rest: insert a rest. Supports all note lengths supported by square waves
set label: write an initialisation value to one of the four labels
conditional jump: takes a label number, condition, decrement flag, and jump offset. The command looks at label [0..3] and tests it for a condition, optionally decrementing the label. This can be used for conditional jumps, unconditional jumps, and repeating a section of music a number of times
Future support is planed for setting note decay and fadeout, PCM data, triangle waves, and noise
Synchronisation and loops/repeats are achieved through labels. To synchronise two channels, you can have one wait on a label that the other one writes. To implement loops and repeats, use a label write to set the repeat count, and then use a conditional jump with label decrement.
GPU
The GPU is designed around sprites and tile graphics, with a max of 128 sprites, of which 64 are displayable per scanline. The tile size is 32×32, and so a 640×480 screen becomes 20×15=300 background tiles.
State Machines
The GPU is divided into three state machines: background tile processing (BG), sprite search, and foreground sprite processing (FG).
GPU processing starts when HDMI signals the GPU to start a new scanline, which runs the BG processing and sprite search state machines in parallel. Sprite search is pretty simple. It looks at all 128 sprites for the first 64 that intersect the current scanline, and adds them to a list. BG processing is a bit more involved. It looks at each pixel in a scanline and works out what BG tile it lives in. It then looks up that tile’s index in GPU RAM, and uses that index to fetch graphics data for the pixel from graphics tile ROM. The graphics tile data is then used as an index into a colour palette to get the background pixel colour. Lastly, it determines the final colour by pulling from the FG sprite FIFO to see if there is a sprite overlapping this pixel and whether its transparent. This final colour is added to an HDMI FIFO for scanout to consume.
BG and FG both need to share a read port for graphics tile ROM, and so they can’t run at the same time. So when BG processing reads the final pixel’s data from the ROM, it then signals FG sprite processing to begin. FG processing does a parallel reduction of the 64 intersecting sprites found by the sprite search pass, and finds the first one to intersect the current pixel. It then looks up that sprite’s pixel in graphics tile ROM to get it’s palette index, and to see if it’s transparent. Note that FG must always run one scanline ahead of BG so that BG processing has the expected data in its FG FIFO.
The GPU is also responsible for signalling the CPU when a new scanline is started, when BG processing finishes, and when FG processing finishes. The CPU can then poll on an MMIO status register to wait for a specific part of a scanline to finish. This is useful for when you only want to change tile indices, and need to wait for BG processing but not FG processing to finish for the current scanline. Or maybe you want to change sprites for the next scanline, and therefore need to wait for FG processing to finish. There is also logic in there to signal the CPU as early as possible, to make up for the round trip latency of the CDC FIFO used to signal the CPU, and the time it takes for a CPU register write to be seen by the GPU.
Palettes
Currently there are 8 background palettes with 8 colours each. The 32×32 background tiles are grouped into 64×64 supertiles, where each tile in a supertile uses the same palette. This means a screen becomes 10×8=80 supertiles, which is alot of data for the CPU to update. To make it a bit more convenient to update sparse indices without the CPU constantly changing the destination address, I encode the address in a similar way to what I use for DMA.
address = dest index (7b), dest X inc (3b), dest Y inc (2b), writes per row (4b)
Just like DMA, every time a new palette number is written, the destination address is automatically changed according to the pattern. And just like the DMA encoding, this allows you to update a linear array of indices, a sparse block of indices, a row of indices, or a column.
There is a similar trick when updating the colours in the palettes. The start address encodes start palette, start colour withing the palette, num colours per palette to update, and colour increment. So you could start at palette 2, and update colours 1, 4, and 7 in all subsequent palettes without ever the CPU changing address.
CPU
The CPU runs at 10MHz, and has a three stage pipeline with no hazards. It reads 16-bit instructions from a 4096 deep instruction memory ROM bank.
ISA
The CPU utilises a RISK ISA. This is not a typo or an acronym, I just think you’re taking a big RISK if you expect it to correctly execute instructions. It currently has the following instructions
add/sub
shift
bitwise: contains a 4 bit function field that specifies AND, OR, XOR, NOT
popcnt
mov 8-bit literal low
mov reg
insert 8-bit literal high
load
pop
pack
unpack
jump
branch if zero
branch if not zero
branch if carry
branch if negative
call
return
store
push
compare: compare register with register, or register with literal
nop
Fun facts:
All branch and jump instructions have two forms: one where the instruction encodes a literal offset, and another where it encodes register number that holds the offset. The instruction after any PC-modifying instruction is considered a branch delay slot.
Mov 8-bit literal low is usually used in conjunction with insert 8-bit literal high to build 16-bit literals. The low mov instruction will write 8 bits to the destination’s LSB8, and zero out the MSB8. Insert leaves the LSB8 as it is, and inserts 8 bits to the MSB8.
And then there is pack/unpack. I wanted a fast way to extract some bits from a field in a register, update the value, and insert the new value back in, but there weren’t enough bits available for the pack. The initial solution was to have unpack set an internal insert mask that pack then uses when reinserting the bits. This mask persists as long as you don’t do another unpack, and so it can be used for multiple packs in a row. I am not 100% in love with this, and am currently considering other solutions such as implicit pairs of aligned registers to save bits for this instruction.
Memory System
All ROMs and RAMs are grouped into the appropriate sounding but vaguely named Memory System. It is also home to the CPU-accessible MMIO registers used to program other bits of the hardware. The CPU accesses these via load and store instructions to four aperatures.
CPU accessible apertures
MMIO: RW, aperture for MMIO registers
RAM: RW, aperture for CPU accessible RAM
ROM: RO, aperture for reading from ROM
tile indices: RW, currently unused, but eventually shares a GPU RAM write port with DMA
So for example, a write to MMIO might look like this
The 16 bits of address and 2 bits of aperature form a 18-bit address. The memory map then becomes:
aper offs CR CW GR GW DR DW
0x00_0000 1 1 0 0 0 0 <= start of RAM
0x00_FFFF 1 1 0 0 0 0 <= end of RAM
0x01_0000 1 0 0 0 1 0 <= start of general ROM data
0x01_FFFF 1 0 0 0 1 0 <= end of general ROM data
0x02_0000 1 1 1 1 0 0 <= start of MMIO regs
0x02_FFFF 1 1 1 1 0 0 <= end of MMIO regs
0x03_0000 0 0 1 0 0 0 <= start of gfx tile data ROM
0x03_FFFF 0 0 1 0 0 0 <= end of gfx tile data ROM (131,072 bytes, 341 tiles, 1.14 screens)
(memory map doesn't include internal GPU RAM)
RAMs and ROMs
The memory system encompasses the following RAM and ROM banks:
CPU RAM: 16-bit RAM accessible to the CPU
CPU ROM: 2048 deep ROM of 18 bit halfwords. CPU can only access the LSB16 of each halfword
GPU RAM: 1024 deep RAM of 18 bit halfwords. Each halfword stores two 9-bit indices into tile ROM
GPU graphics tile ROM: 65,536 deep ROM of 18-bit halfwords
The sizes need a bit of clarification. A graphics tile is a 32×32 pixel block of image data, where each pixel is a 3-bit palette index. So a single 18-bit halfword stores palette indices for six pixels. So to store one row of a 32×32 tile requires six halfwords (with four bits wasted at the end), and a whole tile is 32×6 = 192 halfwords per tile. A 640×480 screen is covered by 20×15=300 tiles, and so one screen worth of data would require 57,600 halfwords. Graphics tile ROM is 65,536 deep, so we can store about 1.14 screens worth of tiles. This isn’t great, and I plan to improve it, but for the time being do plan on reusing graphics tiles alot.
GPU RAM needs to store 9-bit indices for the 300 background tiles. This works out to 150 halfwords, and yet the RAM is 1024 deep. This is because the smallest BRAM primitive on the board is 18kbit. I should probably look into finding other uses for the unused memory.
Finally, CPU ROM has a bit of a dual nature. It’s 18-bits wide, but the only client that can access the whole 18 bits is DMA. Only the LSB16 of each halfword is visible to the CPU. I wish I had a great excuse for why this is, but the jam was only 48 hours long and I jumped into making the CPU before realising everything else in the system should be 18 bits.
Gather/Scatter Pattern DMA
DMA is how background graphics tile indices are transferred from ROM to the GPU, and is clocked with the GPU clock. There are three MMIO registers used to program and kick off DMA transfers
num Y tiles: 4 bits, number of tiles to transfer in the Y direction, [1..15]
DMA config reg 1
dest start addr: 9 bits, destination start, [0..299] tiles
num X tiles: 5 bits, number of tiles to transfer in the X direction, [1..20]
src X inc MSB2: 2 bits, the MSB2 of the source X increment
DMA config reg 2
src X inc LSB3: 3 bits, source X direction increment, [0..20] tiles
src Y inc: 4 bits, source Y direction increment, [1..15] tiles
dest X inc: 5 bits, destination X direction increment, [1..20] tiles
dest Y inc: 4 bits, destination Y direction increment, [1..15] tiles
Writing to that final register is what initiates the DMA transfer. This can be used to do a few useful things. First, you can copy data linearly, or copy a packed block of indices to a packed area in GPU RAM. You can also copy a packed block of indices to a sparse area in GPU RAM, and vice versa. Finally you can splat a single source index into either a packed or sparse area in GPU RAM. Here is an example from the SDK katakana sample
Don’t feel bad, even I can’t remember how my own DMA engine works
Finally, there is a 16-deep DMA request queue. This was supposed to be a quick hack get some of the functionality of DMA chains. However the DMA status MMIO registers aren’t currently hooked up, so be careful not to overflow the FIFO. I will have to fix this eventually.
Controller
The controller was “designed” to feel “familiar” to retro gamers. It has a d-pad, two buttons, plus start and select.
This controller somehow feels familiar to retro gamers
The latest controller data is sampled at roughly 625KHz. It’s probably safe to clock it a bit higher, but the japanese datasheet for the shift register is not very clear on the maximum clock speed when voltage is 3.3v, so I kept it under 1MHz just to be safe. The CPU can query the latest controller data at any time via MMIO register. The Vivado constraints for PMOD port JD are set up as the following
Dev Environment and IDE
Current system requirements are
high tolerance for crap
low expectations
Windows10 64 bit
Because you can’t make games without a proper IDE, I decided to write one using internet snippets of C#, a garbage language with no redeeming value. The theme I am going for is making people long for the days of PS2 CodeWarrior, if you know what I mean. Currently you can build code and data, verify and connect to devkits, and upload executables and data to them. Eventually I’ll add sound and graphics editors
IDE tab for editing and assembling code
IDE tab for devkit management
Host Target Comms
Host target communication is done over UART, with 8 data bits, 2 stop bits, and no parity. Parody, on the other hand, is enabled for this entire project. Host sends the target update files, consisting of
The first four section headers (0001, 0010, 0100, 1000) correspond to the four flashable ROMs: code, data, graphics tile, and audio. A write to any of these ROMs will trigger a devkit reset, and light up the corresponding colour LED on the Arty. Yellow means a particular ROM will be updated, green means that ROM’s update succeeded, and red means the ROM data failed the checksum test.
Other section headers include confirm (send a message to the host when the IDE 確認 button is pressed), LED on (light up some LED pattern), and eventually debugger messages should I ever decide to try and make one.
Special Thanks
Extra special thanks to Rupert Renard, Mike Evans, and the rest of hardware twitter for being so generous with your advice and patient with my stupid questions. Thanks to Colin Riley for the expertly crafted HDMI PMOD that made HDMI possible. Also shout out to Ben Carter (yes, that Ben Carter. The Super Famicom ray tracing one) and Laxer3A for working on what is arguably two of the coolest projects out there, and inspiring me to keep pushing.
FAQ
why 18 bits? Two reasons. First, with ECC disabled, a block RAM byte is 9 bits. This seemed pretty useful at the time, so I just designed everything around that and the numbers worked out really well. Second and most important, Jake Kazdal thinks he’s so cool for calling his company 17bit, and I just felt like I needed to one-up him.
Console X does it this way. Why don’t you? Because its more fun to try and make up your own weird ways to do things without copying others. Sometimes you come up with the same solution others did, and sometimes you make something worse. All that matters is you have fun in the process!
How do I become a registered developer? I dunno, sign an NDA and pay a developer fee to The City Of Elderly Love animal shelter?
Is everything rigorously verified/validated, and confirmed working? LOLZ no. I do have lots of SVA asserts, though, if that makes you feel better.
This post discusses the blocks used in building up, launching, and executing shader work. Because shaders can’t (yet) access memory in a general purpose way, pixel shaders are focused on rather than compute. The rasterizers will be covered in-depth in another post. Before getting started, the following table summarises some of the more commonly used terms and acronyms used throughout this post. Tooltips, shown in boldboldトロフィーを獲得しました: 初めてのツールチップ, are also added in the beginning of each section to make looking up acronyms easier
Term
Meaning
Notes
Nami
vector of 8 pixels/lanes
This is also the ALU width
SDN
Setup Data for Nami
No relation to SDN48
AKB
ALU Kernel Block
No relation to AKB48
NMB
Nami Management Block
No relation to NMB48
SKE
Shader Kernel Executor
No relation to SKE48
STU
Shader Texture Unit
No relation to STU48
ELT
Export [Lit | Luminous] Texels
No relation to Every Little Thing
Figure 1: Terms and acronyms used in this post
rasterizer overview
Figure 2: Twenty rasterizers cover a total of 640×32 pixels
Each rasterizer covers a 32 by 32 pixel screen tile. With a fixed screen resolution of 640×480, the twenty rasterizers together operate on a 640×32 row of screen tiles. Before pixel shaders were added, each rasterizer had its own bank in the render cache, and would output the new blended colour (using the previous colour, the new per-vertex barycentric interpolated colour, and a programmable blending function) and GPU metadata to it. These banks are double buffered so that the rasterizers render to bank N while HDMI scans out the data in bank N^1. Think of it like racing the beam, but instead of a single scanline, you have the time HDMI takes to scan out a tile row. This works out to be
So if a rasterizer takes 3072 clocks to process a triangle for a 32×32 tile, this works out to 67 triangles per rasterizer per tile row per frame. And since hardware manufacturers like to maximise stats using unlikely scenarios, if every screen tile row has its own set of triangles, then the rasterizers process a maximum of 60,300 triangles per second, and output pixels at a rate of 1.24 Gpix/sec.
Things to eventually fix: The rasterizers initially worked on pixel pairs, and processed all three triangle edges in a single clock. However this used up too many DSP slices and made it hard to meet timing. I need to re-investigate whether I can use what I learned about meeting timing this last year to hit the initial target of one triangle taking 512 clocks rather than 3072.
Due to a current limitation with the ISA, the rasterizers are still outputting colour rather than barycentric weights. The pixel cache address and new per-vertex barycentric interpolated colour are output to the SDN for use in shaders. Unfortunately the previous colour isn’t currently available due to losing the ordering guarantee that came from the rasterizers directly writing the cache.
In the previous design, all twenty rasterizers had to stay in sync, meaning you could cull triangles based on vertical position but not horizontal. With the new shader system, this limitation has been removed, and so horizontal culling should eventually be added.
architecture overview
As shown in Figure 2, the twenty rasterizers are grouped into ten pairs of two. Each rasterizer pair outputs pixels to an SDNSDNSetup Data for Nami. This takes in pixels from a pair of rasterizers and packs them into an eight lane wide Nami which packs the pixels into a eight lane vector called a NamiNamiAn eight lane vector, and the native width of the ALU. Once a full Nami is built up, or a hang-preventing timer expires, the Nami is then sent to the AKBAKBALU Kernel Block. This contains all other shader blocks, and distributes incoming Nami to the NMBs and assigned to one of four NMBsNMBNami Management Block. This block tracks up to four Nami, and handles the selection of which ones to send to the AKB for execution. It holds the Nami dynamic data, which is essentially the execution state (PC, lane mask, flags, etc). Each clock, the AKB selects the next NMB, receives a Nami from it, and sends that Nami to the SKESKEShader Kernel Executor. Contains the pipeline and ALU for executing shader instructions for execution. Finally, export instructions will send the final colour and cache address to the ELTELTExport (Lit | Luminous) Texels. This is the export block. It takes in an exported Nami, and routes each of the pixels to the appropriate shader cache bank for export to the shader cache.
SDN
The SDN takes in pixels from a pair of rasterizers, and packs them into an eight lane NamiNamiAn eight lane vector, and the native width of the ALU. There was quite a bit of experimentation done wrt the number of rasterizers that share an SDN. Larger numbers (4+) can build up a full Nami faster, but can introduce quite a bit of logic complexity in the number of possible input cases and overflow cases. Two rasterizers was settled on because the number of overflow cases is only one.
Figure 3 below shows a few of the possible cases the SDN has to handle. In the first case (upper left) we start with a Nami that has seven out of eight slots full. We get a valid pixel from rasterizer A and no pixel from rasterizer B. Pixel A is placed into the final slot in the Nami, and the completed Nami is sent to the AKBAKBALU Kernel Block. This contains all other shader blocks, and distributes incoming Nami to the NMBs. The SDN then starts over with an empty Nami.
Figure 3: a few possible SDN input and overflow cases. Red X indicates an already filled slot
The second case (upper right) shows the opposite. A valid pixel is received from rasterizer B but not from A. B’s pixel completes the Nami, it’s sent to the AKB, and the SDN starts over again with an empty Nami.
In the third case (lower left), we get valid pixels from both rasterizers A and B, but this time the Nami has two unfilled slots. Both pixels A and B are placed in the Nami, it’s sent to the AKB, and the SDN starts over again with an empty Nami.
The final case shows the one possible overflow scenario. Two valid pixels are received but the Nami only has one available slot. Rasterizer A’s pixel completes the Nami, which is sent to the AKB, but then the SDN starts over with a one pixel Nami, containing pixel B. Note in all of the above cases, a full Nami is sent. It’s possible for there not to be enough pixels to form a full Nami. To prevent hangs, a 32 clock timer is reset on every new pixel. If the timer goes down to zero, a partial Nami will be sent.
Notes on rearchitecting: because the rasterizers currently can process one triangle edge per clock, or one triangle every three clocks, the SDN relies on this to reduce logic. If the rasterizers are rewritten to support one triangle per clock, the SDN needs to be redone as well.
Things to eventually fix: to simplify the cache design each rasterizer works on screen pixel R + 20N. So rasterizer 0 would process pixels 0, 20, 40, 60, 80, etc. Rasterizer 1 would process pixels 1, 21, 41, 61, 81, etc. Because of this more partial Nami end up getting sent than would if a quad pattern was used. This was a simplification made when the project started to reduce muxes and help meet timing, and should definitely get fixed before texturing is added.
AKB and NMBs
The AKB has four functions:
take in NamiNamiAn eight lane vector, and the native width of the ALU from an SDNSDNSetup Data for Nami. This takes in pixels from a pair of rasterizers and packs them into an eight lane wide Nami, and assign them to one of the four NMBsNMBNami Management Block. This block tracks up to four Nami, and handles the selection of which ones to send to the AKB for execution. It holds the Nami dynamic data, which is essentially the execution state (PC, lane mask, flags, etc)
each clock, select the next NMB via round robin, receive a Nami from it, and pass the Nami on to the SKESKEShader Kernel Executor. Contains the pipeline and ALU for executing shader instructions for execution
receive a Nami’s updated dynamic data (new active lane mask, status flags, program counter, retire status, etc) from the SKE, and route it back to the proper NMB
when all NMBs are full, send a backpressure signal to the SDN, which clock gates the SDN and rasterizer until Nami slots are freed up
Figure 4: an AKB connects to an SDN, and contains the interesting shader bits
The AKB takes as input Nami from an SDN, and must distribute them to the next non-full NMB. Because of the way NMBs are selected for execution via round robin, it’s preferable to also add new Nami via round robin as well, to help saturate the ALU. The AKB keeps track of the last NMB to receive a new Nami, looks at the full flags of each NMB, and determines which NMB the next new Nami will be sent to.
Because pipeline latency requires at least four clocks between consecutive executions of the same Nami, the AKB round robins the four NMBs with no ability to skip empty NMBs. In the case where an empty NMB is selected, a null nami is passed to the AKB to avoid side effects. Once the next NMB is selected, and it’s Nami is received, the AKB appends the NMB number and Nami ID, and passes the data to the SKE for execution. The NMB number and Nami ID are used to route the updated dynamic data returned from the SKE back to the right place.
The NMBs are fairly simple. They store the execution state, consisting of constant and dynamic data, for up to four Nami. They also choose the next Nami to be presented to the AKB for execution, maintain status flags like is_full, and handle the add/retire management logic. Dynamic data consists of things that can change during execution, like the valid lane mask, status flags, program counter, and retire status. The const data is the previous colour for a pixel, the new barycentric interpolated colour, and the address in the shader cache. Because the Nami in the NMB can be sparse, the NMB remembers the last Nami sent for execution, and tries to fairly select a different one to run next time. This is mainly to help hide some of the latency once texturing is implemented.
Figure 5: simplified view of NMB functionality
In the above image, the NMB has two valid Nami (slots 0 and 2) indicated by the valid mask V. The generated add mask, A, is 4’b0010 meaning the incoming new Nami will be added to slot 1. R is the retire mask coming from the AKB/SKE, and in this case means the Nami in slot 2 is retiring. Each clock, the new valid mask is calculated as V = V | A & R which both adds a new Nami and retires any Nami that had their export request granted. The full signal is calculated as the bitwise AND reduction of the valid mask.
Notes on rearchitecting: The AKB and NMBs take a few clocks to update state, and therefore rely on an SDN not being able to provide more than one Nami every four clocks. If the SDN bottleneck is removed, it will require a significant updating of the AKB
Things to eventually fix: right now, every assigned Nami is always ready to run. There is no ability to skip a Nami that is waiting on a texture fetch or an i-cache miss. This is definitely going to need fixing as texturing is added, and if compute shaders requiring general DDR3 memory access are added.
SKE
SKE, shown as a red box in Figure 4, stands for Shader Kernel Executor. It contains the execution pipeline, register file, i-cache, and ALU used in executing NamiNamiAn eight lane vector, and the native width of the ALU.
Each clock, the AKBAKBALU Kernel Block. This contains all other shader blocks, and distributes incoming Nami to the NMBs gets a Nami from the next NMBNMBNami Management Block. This block tracks up to four Nami, and handles the selection of which ones to send to the AKB for execution. It holds the Nami dynamic data, which is essentially the execution state (PC, lane mask, flags, etc), and passes it to the SKE. In the case where an NMB sends the same Nami back to back, four clocks isn’t enough time for the updated dynamic data from the first execution to reach the NMB, and so a forwarding path is needed. The ALU sends the updated dynamic data and Nami ID both to the originating NMB, and also over the forwarding path to the SKE input. If the current Nami ID is equal to the forwarded Nami ID, then the Nami is being executed twice in a row, and forwarded data must be used to avoid out of date dynamic data. This forwarding path is shown both in Figure 4 and the in following waveform.
Figure 6: single Nami data forwarding case
The above waveform shows the case where only one Nami exists and its assigned to NMB0. The waveform starts at (A) when fetch_nami goes high, meaning the AKB has selected NMB0 to send a Nami. One clock later (B), valid_nami_from_akb goes high when the SKE receives the Nami and it enters the execution pipeline. Four clocks after fetch_nami originally went high, it goes high again (C), and NMB0 sends the same Nami as last time. At this point, NMB0 still hasn’t received the updated dynamic data from the first execution of the Nami, and so it sends stale data. The SKE detects this case, and asserts use_forwarded_data (D). Finally, at (E) the updated dynamic data from the first execution arrives at NMB0.
Handling of the export instruction is different than that of other instructions. It’s currently the only instruction that can fail and require a retry. The ELTELTExport (Lit | Luminous) Texels. This is the export block. It takes in an exported Nami, and routes each of the pixels to the appropriate shader cache bank has a small Nami FIFO for holding export requests, and if this FIFO is full an export request can’t be granted. Retry is implemented simply by not updating the program counter if an export request is not not granted.
A successful export grant relies on the data forwarding mechanism outlined above. Export functions as an end of shader signal, and will retire the Nami in the NMB, but as shown in Figure 6 it’s possible for the NMB to issue the Nami for execution one more time before seeing the retire signal from the SKE. It’s for this reason that the dynamic data contains a successful export grant signal, which will insert a NOP if forwarded data is used.
The register file consists of two banks of eight registers each. Instructions that take two input operands must take one from bank A and the other from bank B. This is to make it easier to achieve two register reads per clock, since reading asynchronous distributed RAM on posedge and negedge clk makes it difficult to meet timing. Instruction output operand encoding can specify bank A, bank B, or both. The registers themselves are eight lanes wide, the same width as a Nami, and each lane is 16 bits. The total register file is 16 (registers/Nami) x 4 (Nami/NMB) x 4 (NMBs/AKB) x 8 (lanes) x 16 (bits/lane) = 32,768 bits per AKB. Despite the size, using BRAM would be wasteful as native BRAM primitives don’t support read widths of 128 bits, and can’t provide the byte write enable bits needed to implement lane masking, meaning a 18k BRAM per two lanes would have to be used, which leaves each BRAM only used at 25% capacity. The current implementation uses distributed RAM, but this has drawbacks as well as it requires high LUT usage for multiplexing reads.
notes on rearchitercting: because Nami do not currently have the ability to wait, the way the i-cache is being used is more like a separate program memory. It will go back to being used as an actual cache once the new DDR3 controller is done, and work implementing texturing begins
ELT
ELT stands for Export (Lit | Luminous) Texels, and is the block responsible for exporting to the cache. It places incoming NamiNamiAn eight lane vector, and the native width of the ALU data from the SKESKEShader Kernel Executor. Contains the pipeline and ALU for executing shader instructions into a Nami FIFO, and then for each pixel in the Nami, adds it’s colour/metadata/cache address to one of two pixel FIFOs for consumption by the shader cache. The reason there are two pixel FIFOs is that two rasterizers connect to a single SDNSDNSetup Data for Nami. This takes in pixels from a pair of rasterizers and packs them into an eight lane wide Nami / AKBAKBALU Kernel Block. This contains all other shader blocks, and distributes incoming Nami to the NMBs, and therefore a Nami can contain a mix of pixels to be written to either cache bank in the pair. The image below shows an example of this. Letters A through H represent Nami data, and [0,1] specifies which cache in the pair to write the colour to.
Figure 7: various FIFOs inside the export block
When the Nami FIFO is not empty, the ELT takes the next entry and loops over each pixel, distributing it to one of the two pixel FIFOs, depending on the cache pair number. In the above example, pixel data A, D, and G are routed to pixel FIFO 0, to be consumed by cache bank 2A+0. Confusingly, the A in the bank number is unrelated to pixel data A, but rather stands for AKB number, such that AKB0 connects to cache banks 0 and 1, AKB1 connects to cache banks 2 and 3, and so on.
Because a cache bank can have multiple clients, it’s possible to add pixels to the ELT pixel FIFO faster than the cache consumes them. This case is shown above, where pixel H should be added to pixel FIFO 1, but there is no room. In this case, a backpressure signal is asserted, and the ELT will retry to add the pixel next clock
The image below shows the first ever pixel shader running on hardware, displaying in a small PIP window. It’s not pretty or fancy or advanced, and the shader was only around 7 instructions, but admittedly it felt pretty amazing actually seeing the GPU saturate and having it not mess up.
special thanks
Ben Carter (@CarterBen) for reading the whole thing, even though it was a mess and made little sense
Colin Riley (@domipheus) for both inspiring me with his CPU project, and for sending me the HDMI PMOD that he made